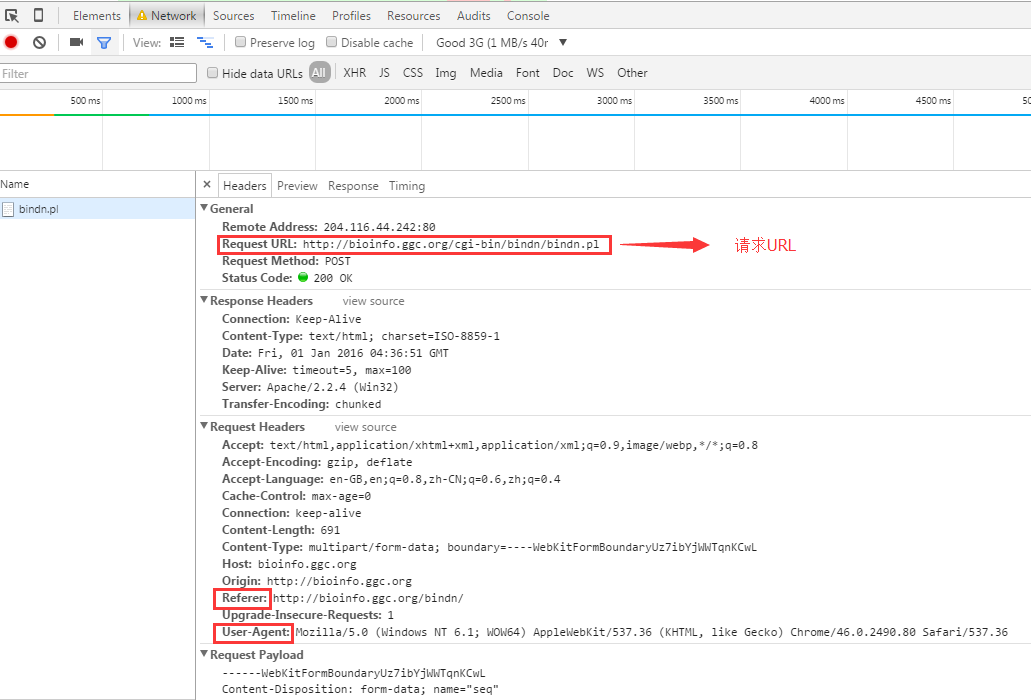
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
"""
Created on Fri Jan 01 09:34:50 2016
@author: liudiwei
"""
import os
import urllib
import urllib2
import cookielib
import re
def scratchData(hosturl, posturl, postData, headers):
cj = cookielib.LWPCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
urllib2.urlopen(hosturl)
postDataEncode = urllib.urlencode(postData)
request = urllib2.Request(posturl, postDataEncode, headers)
print request
response = urllib2.urlopen(request)
resultText = response.read()
return resultText
def BindN(oneseq, outdir):
hosturl = 'http://bioinfo.ggc.org/bindn/'
posturl = 'http://bioinfo.ggc.org/cgi-bin/bindn/bindn.pl'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36',
'Referer' : 'http://bioinfo.ggc.org/bindn/'}
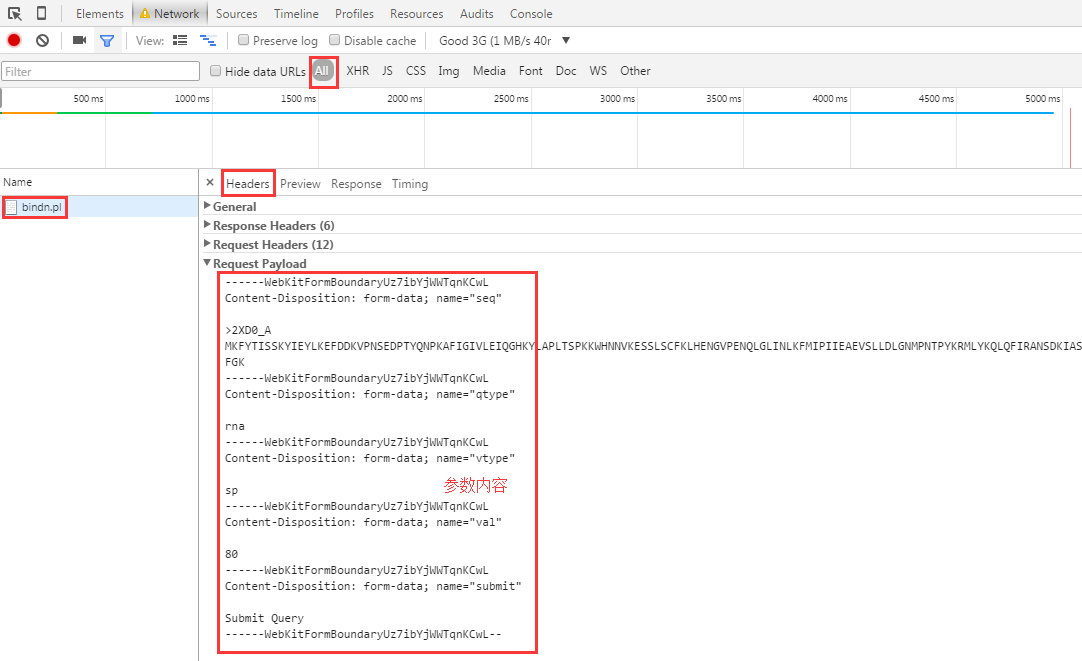
postData = {'seq' : oneseq,
'qtype' : 'rna',
'vtype' : 'sp',
'val' : '80',
'submit' : 'Submit Query'
}
result = scratchData(hosturl, posturl, postData, headers)
print "+++++", oneseq
chainname = oneseq[1:5] + oneseq[6:7]
outfilename = str(chainname) + '.html'
fw_result = open(outdir + '/' + outfilename, 'w')
fw_result.write(result)
fw_result.close()
return result, str(chainname)
def extractBindN(htmlfmt, outfile):
fw_result = open(outfile, 'w')
inputdata = htmlfmt.split('\n')
for i in range(len(inputdata)):
onedata = inputdata[i].strip()
if not onedata:
continue
if '<' in onedata or '*' in onedata:
continue
regText = onedata.split('\t')[0].strip()
if re.match(r'^\d+$', regText) and True or False:
fw_result.write(onedata + '\n')
fw_result.close()
if __name__=="__main__":
oneseq = ">2XD0_A\nMKFYTISSKYIEYLKEFDDKVPNSEDPTYQNPKAFIGIVLEIQGHKYLAPLTSPK\
KWHNNVKESSLSCFKLHENGVPENQLGLINLKFMIPIIEAEVSLLDLGNMPNTPYKRMLYKQLQFIRANSDKIA\
SKSDTLRNLVLQGKMQGTCNFSLLEEKYRDFGK"
outdir = "/home/liudiwei/result"
if not os.path.exists(outdir):
os.mkdir(outdir)
print outdir
result, chainname = BindN(oneseq, outdir)
outfile = outdir + "/" + chainname + ".data"
extractBindN(result, outfile)
|