最近突然对爬虫兴趣倍增,主要是自己想从网上爬点数据来玩玩。前阵子从某房屋出售网爬取了长沙地区的房价以及2016年的成交额,只有几千条数据,量较少,没劲o(╯□╰)o,因此将目标成功地转移到了社交网上,难度显然大了点。爬取社交网站比较鲜明的特点就是需要登录,否则很多东西都无法获取。做了几个小Demo之后发现,人人网的登录还比较简单,验证码的都不用就可以成功登录;知乎虽然携带验证码,但难度算是适中;微博的登录难度稍微大点,因为不仅有验证码,还在传递参数的时候对用户名进行了base64加密。在这篇博文里,主要是以知乎为例,模拟知乎登录,至于数据爬取部分咱们就暂且不谈吧。
环境与开发工具
模拟知乎登录前,先看看本次案例使用的环境及其工具:
- Windows 7 + Python 2.75
- Chrome + Fiddler: 用来监控客户端与服务器的通讯情况,以及查找相关参数的位置。
Github源码下载:https://github.com/csuldw/WSpider.
模拟过程概述
- 使用Google浏览器结合Fiddler来监控客户端与服务端的通讯过程;
- 根据监控结果,构造请求服务器过程中传递的参数;
- 使用Python模拟参数传递过程。
客户端与服务端通信过程的几个关键点:
- 登录时的url地址。
- 登录时提交的参数【params】,获取方式主要有两种:第一、分析页面源代码,找到表单标签及属性。适应比较简单的页面。第二、使用抓包工具,查看提交的url和参数,通常使用的是Chrome的开发者工具中的Network, Fiddler等。
- 登录后跳转的url。
在抓包的时候,开始使用的是Chrome开发工具中的Network,结果没有抓到,后来使用Fiddler成功抓取数据。下面逐步来细化上述过程。
参数探索
首先看看这个登录页面(https//www.zhihu.com),也就是我们登录时的url地址。
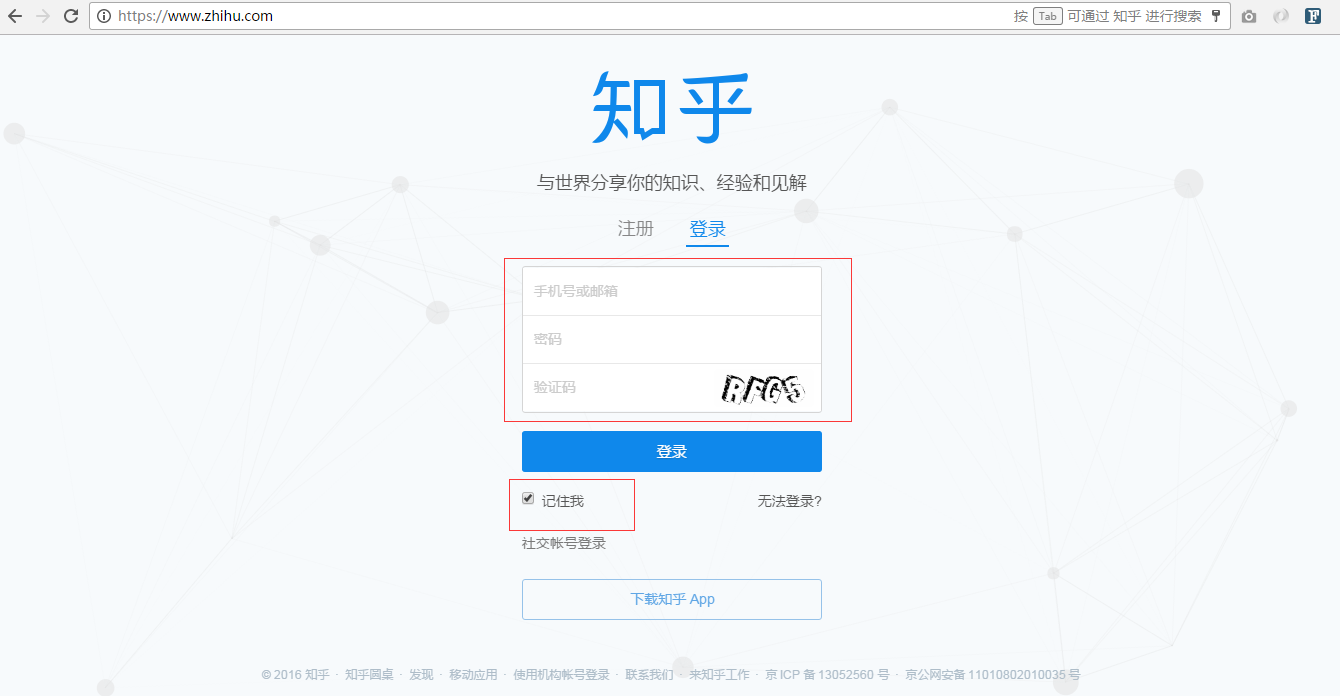
看到这个页面,我们也可以大概猜测下请求服务器时传递了几个字段,很明显有:用户名、密码、验证码以及“记住我”这几个值。那么实际上有哪些呢?下面来分分析下。
首先查看一下HTML源码,Google里可以使用CTRL+U查看,然后使用CTRL+F输入input看看有哪些字段值,详情如下:
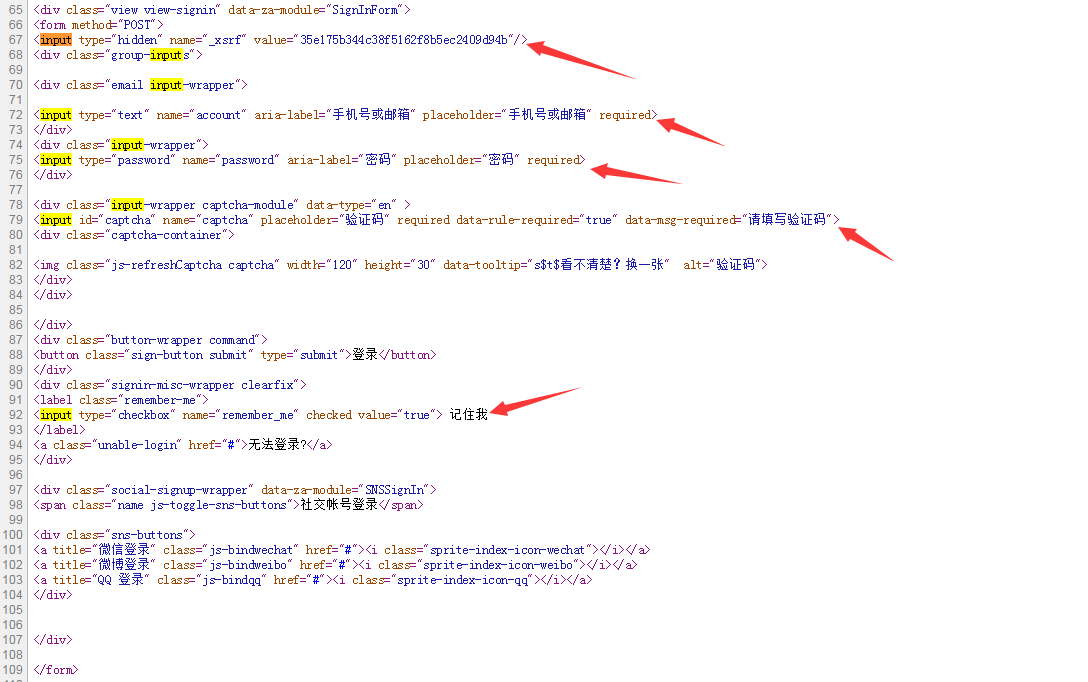
通过源码,我们可以看到,在请求服务器的过程中还携带了一个隐藏字段”_xsrf”。那么现在的问题是:这些参数在传递时是以什么名字传递的呢?这就需要借用其他工具抓包进行分析了。笔者是Windows系统,这里使用的是Fiddler(当然,你也可以使用其他的)。
抓包过程比较繁琐,因为抓到的东西比较多,很难快速的找到需要的信息。关于fiddler,很容易使用,有过不会,可以去百度搜一下。为了防止其他信息干扰,我们先将fiddler中的记录清除,然后输入用户名(笔者使用的是邮箱登录)、密码等信息登录,相应的在fiddler中会有如下结果:
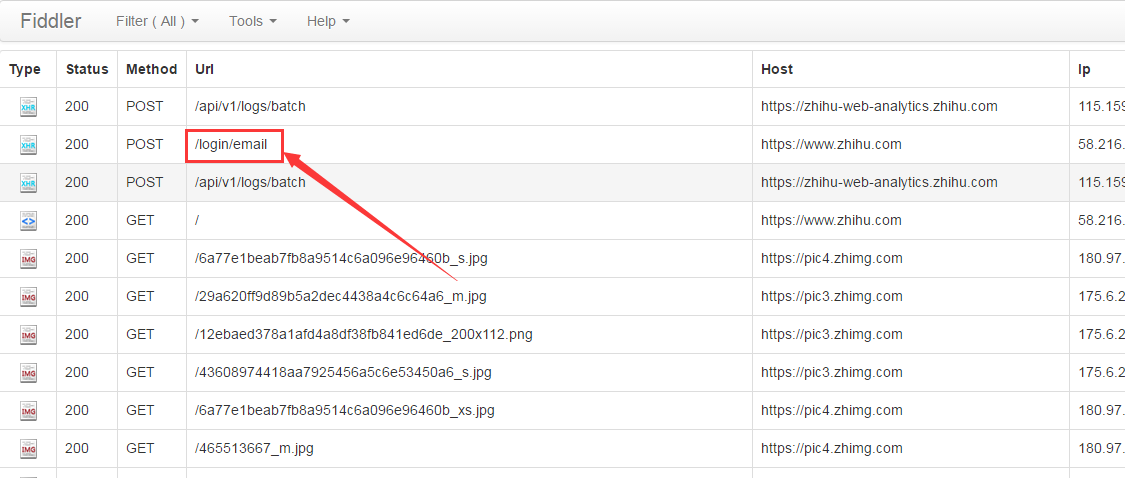
备注:如果是使用手机登录,则对应fiddler中的url是“/login/phone_num”。
为了查看详细的请求参数,我们左键单机“/login/email”,可以看到下列信息:
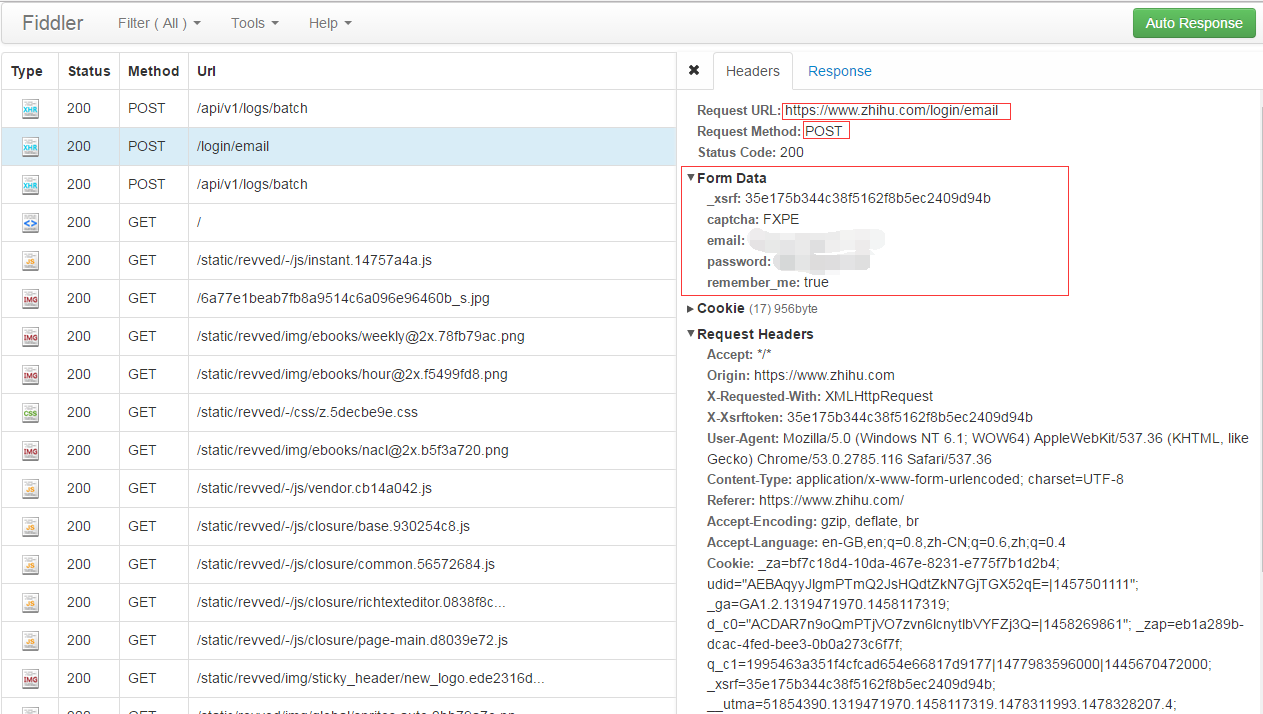
请求方式为POST,请求的url为https://www.zhihu.com/login/email。而从From Data可以看出,相应的字段名称如下:
- _xsrf
- captcha
- password
- remember
对于这五个字段,代码中email、password以及captcha都是手动输入的,remember初始化为true。剩下的_xsrf则可以根据登录页面的源文件,取input为_xsrf的value值即可。
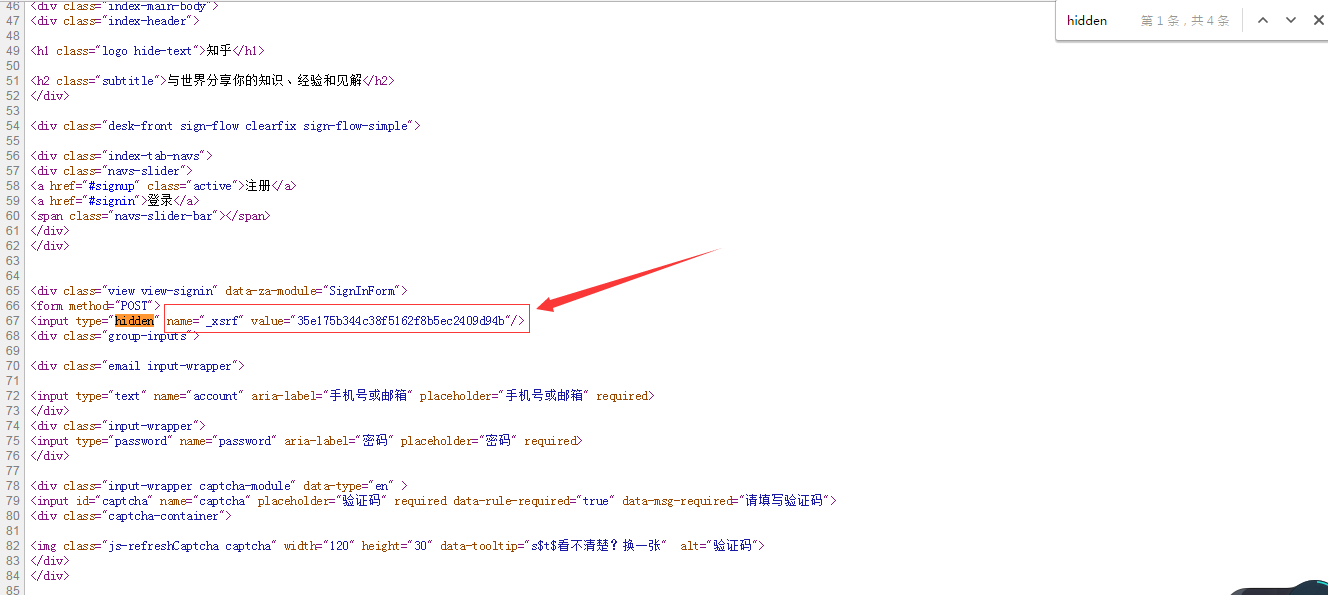
对于验证码,则需要通过额外的请求,该链接可以通过定点查看源码看出:
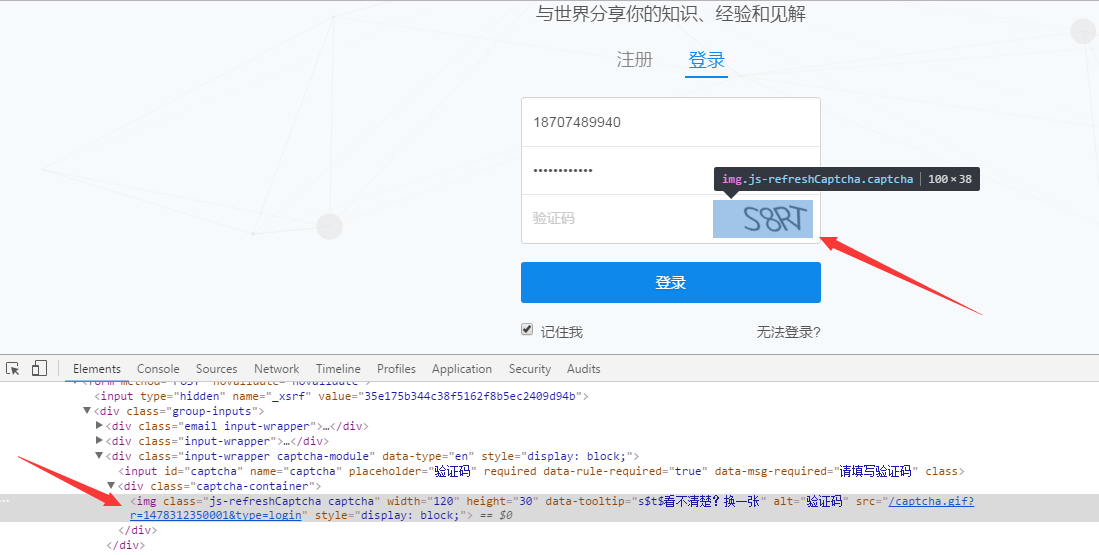
链接为https://www.zhihu.com/captcha.gif?type=login,这里省略了ts(经测试,可省略掉)。现在,可以使用代码进行模拟登录。
温馨提示:如果使用的是手机号码进行登录,则请求的url为https://www.zhihu.com/login/phone_num,同时email字段名称将变成“phone_num”。
模拟源码
在编写代码实现知乎登录的过程中,笔者将一些功能封装成了一个简单的类WSpider,以便复用,文件名称为WSpider.py。
1 | # -*- coding: utf-8 -*- |
关于模拟登录知乎的源码,保存在zhiHuLogin.py文件,内容如下:
1 | # -*- coding: utf-8 -*- |
关于源码的分析,可以参考代码中的注解。
运行结果
在控制台中运行python zhiHuLogin.py,然后按提示输入相应的内容,最后可得到以下不同的结果(举了三个实例):
结果一:密码错误

结果二:验证码错误

结果三:成功登录

通过代码,可以成功的登录到知乎,接着如果要爬取知乎里面的内容,就比较方便了。