上一篇文章小试牛刀:使用Python模拟登录知乎介绍了如何模拟知乎登录,虽然用到了验证码信息,但请求的参数都是原封不动的传递,刚开始接触的时候,觉得难度适中,回头再看的时候,反而感觉挺容易的。在这篇文章,将继续介绍模拟登录。与之前不一样的是,这次选择的对象是新浪微博,难度稍微提升了点,好在以往的许多码友们都留有许多经验贴,经过几番斟酌,微博的模拟登录算是实现了。这两天还在研究如何高性能地爬取微博数据,业余之际乘着还有点记忆,索性将先前的小实验加工成文,算是一份小结吧。下面来看看整个实验过程。
开发工具
一如既往,笔者使用的还是之前的工具,如下:
- Windows 7 + Python 2.75
- Chrome + Fiddler
微博登录请求过程分析
新浪微博的登录有多个URL链接,笔者在实验的时候试了两个,这两个都是新浪通行证登录页面,都是不需要验证码的。一个是 【http://login.sina.com.cn】,另一个是 【https://login.sina.com.cn/signup/signin.php?entry=sso】。两个URL虽然很大部分相同,登录过程中仅仅是传递参数不一样。第一个URL传递的过程对“password”进行了加密,而第二个没有加密,所以如果使用第二个URL进行模拟登录,就简单多了。在这里,笔者决定选择使用第一种方式进行分析,下面来看详细过程。
请求登录过程可归纳为三部分
- 请求登录login.php页面前的参数预获取
- 请求登录login.php页面时的参数分析
- 提交POST请求时的参数构造
Step 1:GET方式请求prelogin.php页面
在模拟登录之前,先观察浏览器登录过程中Fiddler抓到的包,在/sso/login.php打开之前会先使用“GET”方式请求“/sso/prelogin.php”,请求的URL为:【https://login.sina.com.cn/sso/prelogin.php?entry=account&callback=sinaSSOController.preloginCallBack&su=bGl1ZGl3ZWkxOCU0MHNpbmEuY29t&rsakt=mod&client=ssologin.js(v1.4.15)】,可以看看下面这张图:
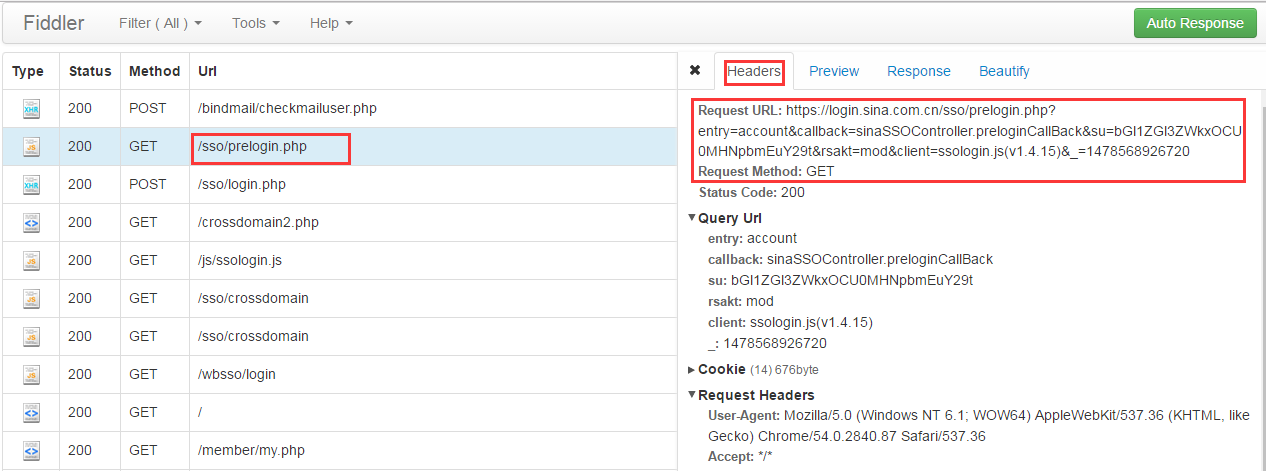
在Fiddler中,可以点击“Preview”查看具体详情,也可以直接将Request URL复制到浏览器上查看,效果图如下:
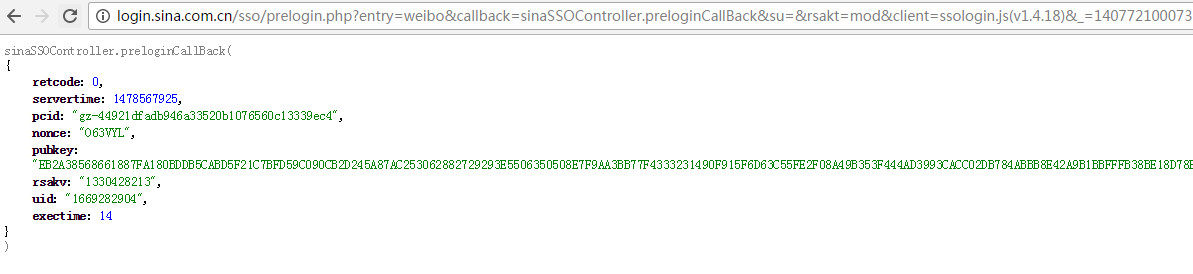
可以看出,这是一个json数据,并且携带了几个参数,我们关心的有以下四个:
- servertime
- nonce
- pubkey
- rsakv
说明一下,之所以认为这几个参数比较重要,那是因为后面对“password”的加密需要用到,对其他参数没有提及的原因是在提交POST时其它的参数并没有用到。好了,为了进行进一步探索,我们从Fiddler的结果可以看出,接下来到了“/sso/login.php”。
Step 2:POST方式请求login.php页面
从这里开始,就进行“login.php”页面的请求分析了(详细的Request URL:【https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)】,后面的时间戳可省略)。点击查看详情,结果图如下:
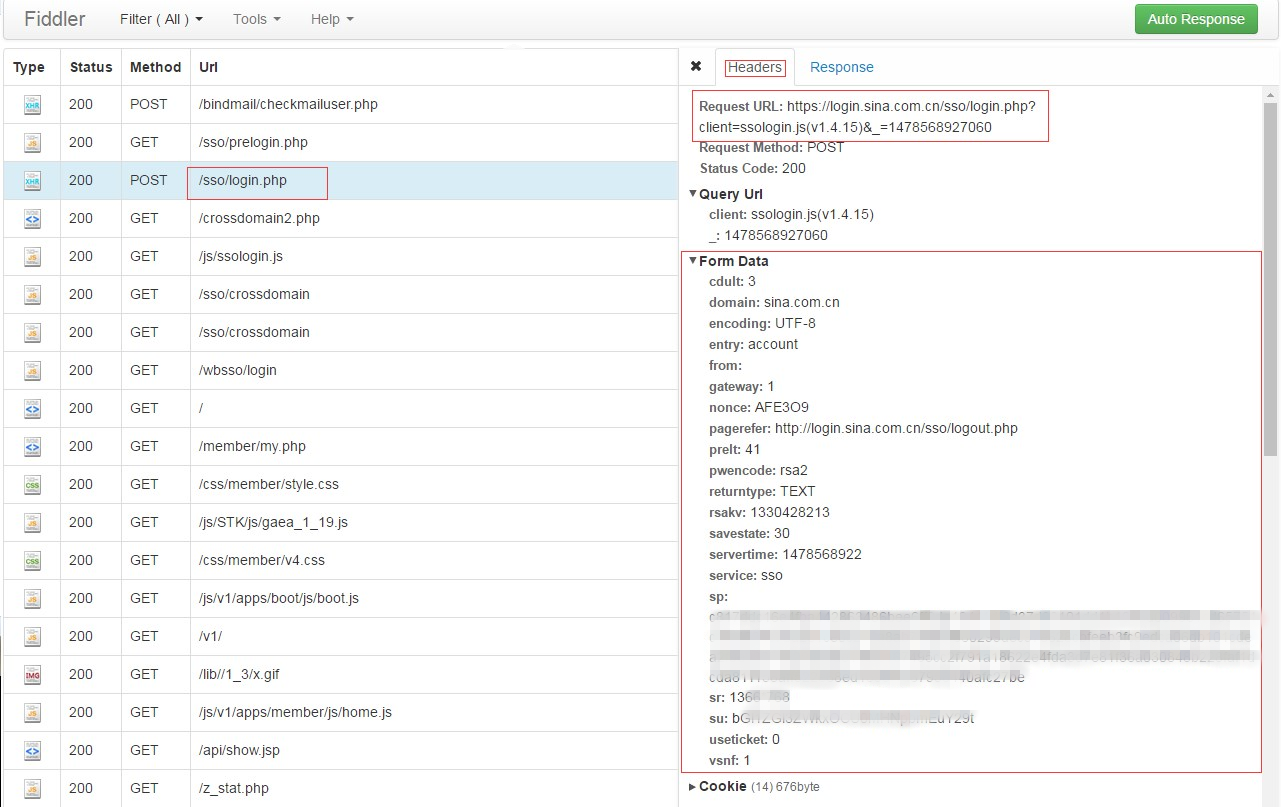
可以发现/sso/login.php页面有如下参数(From Data):
cdult: 3
domain: sina.com.cn
encoding: UTF-8
entry: account
from:
gateway: 1
nonce: AFE3O9
pagerefer: http://login.sina.com.cn/sso/logout.php
prelt: 41
pwencode: rsa2
returntype: TEXT
rsakv: 1330428213
savestate: 30
servertime: 1478568922
service: sso
sp: password
sr: 1366*768
su: username
useticket: 0
vsnf: 1
到了这里,我们大概可以知道我们需要哪些参数了。在From Data 参数列表中,需要我们指定的参数有下面几个:
- servertime
- nonce
- rsakv
- sp:加密后的密码
- su:加密后的用户名
对于参数“nonce”、“servertime”、“rsakv”,都可以从第一步中的“prelogin.php” 中直接获取,而“sp”和“su”则是经过加密后的字符串值,至于具体的加密规则,我们下面通过查看源码分析得出。
Step 3:探索加密规则
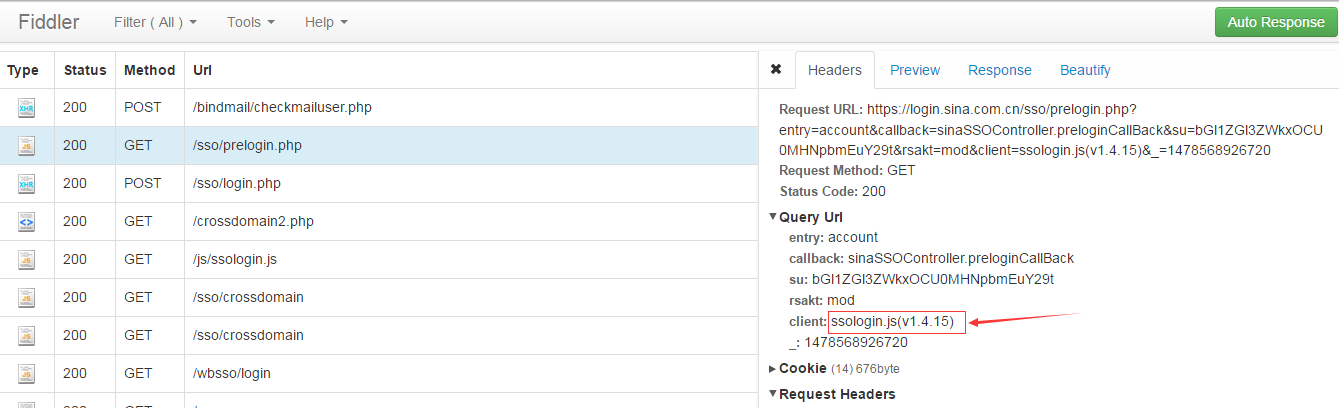
首先看看请求“/sso/prelogin.php”的具体情况,看到“client”为“ssologin.js”,见下图:
然后我们到登录页面https://login.sina.com.cn中查看源码【view-source:https://login.sina.com.cn/】并搜索“ssllogin.js”,接着点击进入ssologin.js文件,这时我们可在文件中搜索“username”字符串,找到与“username”相应的加密部分(需仔细查看+揣测),接着搜索“password”,找到“password”的加密部分,最后分析出“username”和“password”的加密规则。加密部分的代码如下图:
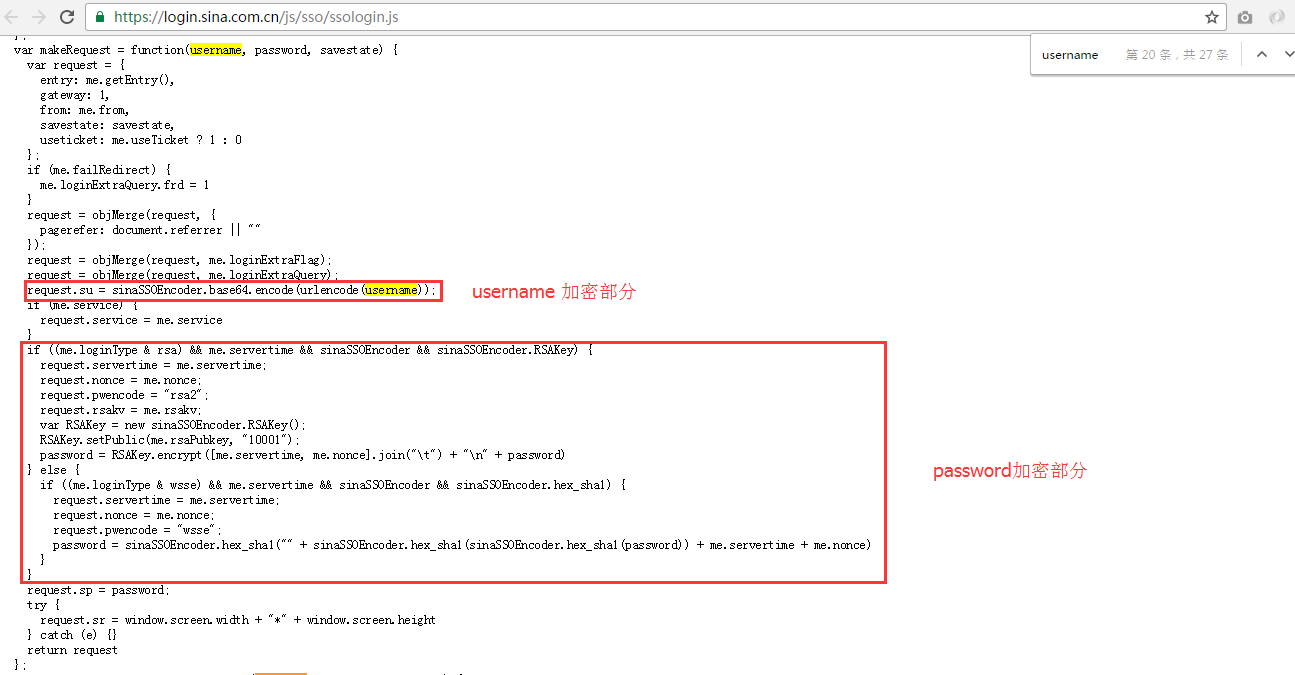
加密用户名的代码:
1 | request.su = sinaSSOEncoder.base64.encode(urlencode(username)); |
加密密码的代码:
1 | if ((me.loginType & rsa) && me.servertime && sinaSSOEncoder && sinaSSOEncoder.RSAKey) { |
微博对于“username”的加密规则比较单一,使用的是“Base64”加密算法,而对“password”的加密规则比较复杂,虽然使用的是“RSA2”(python中需要使用pip install rsa 安装rsa模块),但加密的逻辑比较多。根据上面的代码,可以看出“password”加密是这样的一个过程:首先创建一个“rsa”公钥,公钥的两个参数都是固定值,第一个参数是登录过程中“prelogin.php”中的“pubkey”,第二个参数是加密的“js”文件中指定的“10001”(这两个值需要先从16进制转换成10进制,把“10001”转成十进制为“65537”)。最后再加入“servertime”和“nonce”进行进一步加密。
经过上面的分析之后,发起“POST”请求时的“post_data”基本上已经全部可以得到了,接下来就跟模拟登录其它网站类似了,可以使用“request”,也可以使用“urllib2”。下面来看详细代码部分。
源码实现
Github源码链接:https://github.com/csuldw/WSpider/tree/master/SinaLogin,源码包括下列文件:
- dataEncode.py:用于对提交POST请求的数据进行编码处理
- Logger.py:用于打印log
- SinaSpider.py:用于爬取sina微博数据的文件(主文件)
为了方便扩展,笔者将代码进行了封装,所以看起来代码量比较多,不过个人觉得可读性还是比较良好,算是凑合吧。
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
关于源码的分析,可以参考代码中的注解,如有不理解的地方,可在评论中提出。
运行
直接在Windows控制台运行python SinaSpider.py,然后根据提示输入用户名和密码即可。
运行结果展示

OK,匆忙之际赶出了本文,如有言之不合理之处,可在评论中指出。现在可以成功地登录到微博了,接下来想爬取什么数据就尽情的爬吧。后续笔者将进一步介绍如何爬取微博数据,好了,后会有期吧!