在前几篇博文里,【模拟新浪微博登录:从原理分析到实现】一文介绍了如何登陆微博,【新浪微博数据爬取Part 1:用户个人信息】与【新浪微博数据爬取Part 2:好友关系与用户微博】两篇文章介绍了如何爬取微博用户个人资料、关注者列表、粉丝列表以及发表的微博。那么,在这篇文章里,将介绍如何把前几篇的内容融合到一起,整合成一个完整的新浪爬虫框架。OK,让我们来见证一个爬虫的诞生吧^_^。
本文代码请移步Github:https://github.com/csuldw/WSpider/tree/master/SinaWSpider。
环境说明
- 开发语言:Python 2.75;
- Python相关库:BeautifulSoup、urllib、urllib2、base64、rsa、json、logging、pymongo。
- 数据存储:MongoDB 3.2 + Robomongo 0.9.0 可视化工具
如果你的Python环境里没有上述的某个库,那么使用pip或是easy_install来进行安装。另外,如果你暂时不打算使用MongoDB存储数据,也可在./output目录中查看每个用户的相关信息。
方法封装
为了方便,我们首先将爬取新浪相关的方法都封装到SinaSpider.py文件中,该文件可以说是新浪spider的核心内容,里面主要是SinaClient类,内部方法说明如下。
主要方法
对于整个爬虫项目,外部函数调用内部方法的时候只需要关注以下几个即可:
- login(self, username, password):根据用户名和密码登录sina微博;
- switchUserAccount(self, userlist):用于切换用户账号,防止长时间单账号爬取,其中调用了login方法;
- getUserInfos(self, uid):根据用户ID获取用户个人信息;
- getUserFollows(self, uid, params):根据用户ID 获取用户关注的用户ID列表;
- getUserFans(self, uid, params):根据用户ID 获取粉丝ID列表;
- getUserTweets(self, uid, tweets_all, params):根据用户ID 获取微博,tweets_all是一个list变量。
如果还需要爬取微博其它的数据,可在SinaClient类中补充即可。
辅助方法
对于该爬虫,我们想要的就是让她正常工作,所以为了防止访问次数超限,可在爬取过程中调用switchUserAgent来切换用户代理,或是在使用cookie的时候,将enableCookie中的 enableProxy参数置为True。在SinaClient类中,其它的辅助方法说明如下:
- initParams(self):初始化参数;
- setAccount(self, username, password):设置username与password;
- setPostData(self):设置请求登录时的post_data内容;
- switchUserAgent(self, enableAgent=True):切换用户代理User-Agent;
- enableCookie(self, enableProxy=False):允许存储cookie;
- openURL(self, url, data=None):打开url时携带headers,此header需携带cookies;
- output(self, content, out_path, save_mode=”w”):将文本内容输出至本地。
参数封装
为了方便配置变量,我们将一些需要自己赋值的变量抽取出来,写入到conf.ini文件,而加载该配置文件的代码写与myconf.py中,并在myconf.py文件中定义一些中转变量agent_list 和userlist,方便切换代理和更换用户时使用,同时将配置日志输出的代码写到Logger.py中。另外,对于登录时提交的与post_data 有关的数据都封装到dataEncode.py。对于这几个文件,可概括如下:
- conf.ini:用于配置proxies、headers等参数,其中Sina API的参数需设置成自己的;
- myconf.py:加载配置文件;
- dataEncode.py:用于模拟登录sina时提交的POST数据;
- Logger.py:用于输出日志文件;
在上述文件中,dataEncode.py文件里有个值得一提的参数,那就是encode_post_data方法中的post_data。如果你使用第一个post_data,那么有的账号是需要输入验证码的,在运行本代码时,有的用户无法正常登陆,她会提示你“Login Failed –> 为了您的帐号安全,请输入验证码”,因此,笔者在敲代码的时候将第一个注释掉了,一般使用第二个post_data。别问我怎么知道的,实践才是真理啦。通过封装参数之后,我们只需要将myconf.py 中的userlist 修改成自己的账户列表就可以正常登录了。如果你还想增加代理,那么只需将conf.ini中的proxies 设置称自己的代理即可。
温馨提示:如果你对Sina API感兴趣,并想试下它的用法,那么你可以将conf.ini中的access_token与app_key设置成自己配置新浪API接口时获取的值(请自行查阅相关资料),然后另写一个test方法调用getUserInfo方法便可得到相应的JSON数据。
调用封装
通过上面的方法封装和参数封装,我们可以很方便的进行调用了。这里,我们将代码的执行函数写入到main.py 文件里,后续如果还需要得到什么样的结果以及如何存储这些返回的结果集,都可以在此文件中编写。
- main.py:运行项目的入口文件
结果说明
截止2016年12月25日,该爬虫共可爬取如下几部分信息,每个函数的返回值均为JSON串:
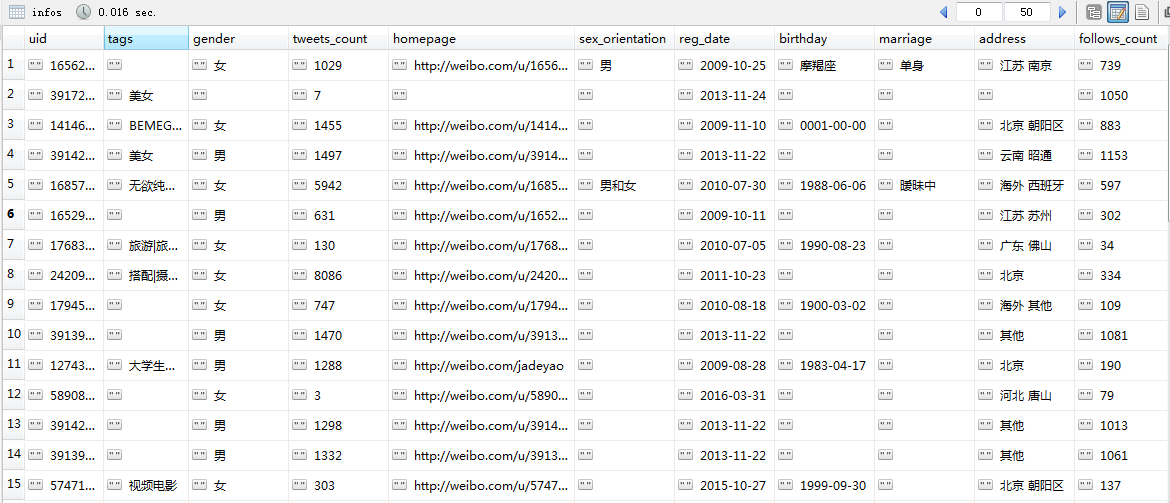
1.getUserInfos获取用户信息
1 | uid:用户ID |
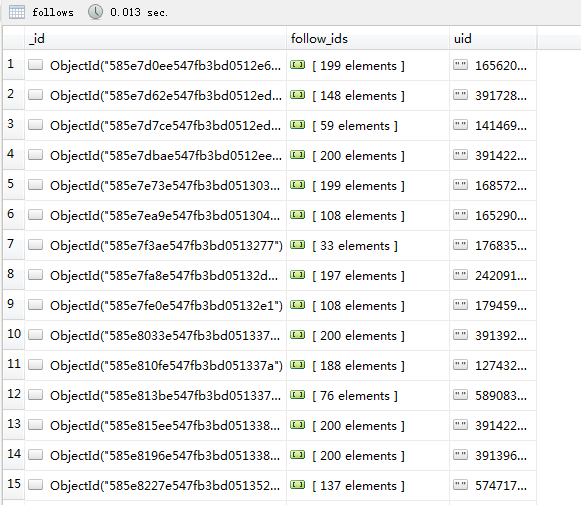
2.getUserFollows获取用户关注人
1 | uid:用户ID |
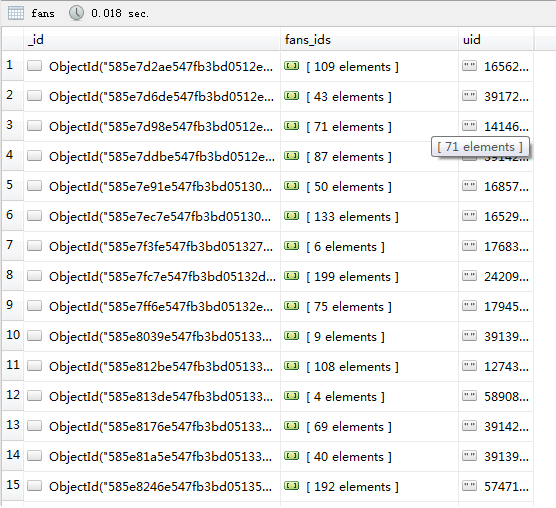
3.getUserFans 获取用户粉丝
1 | uid:用户ID |
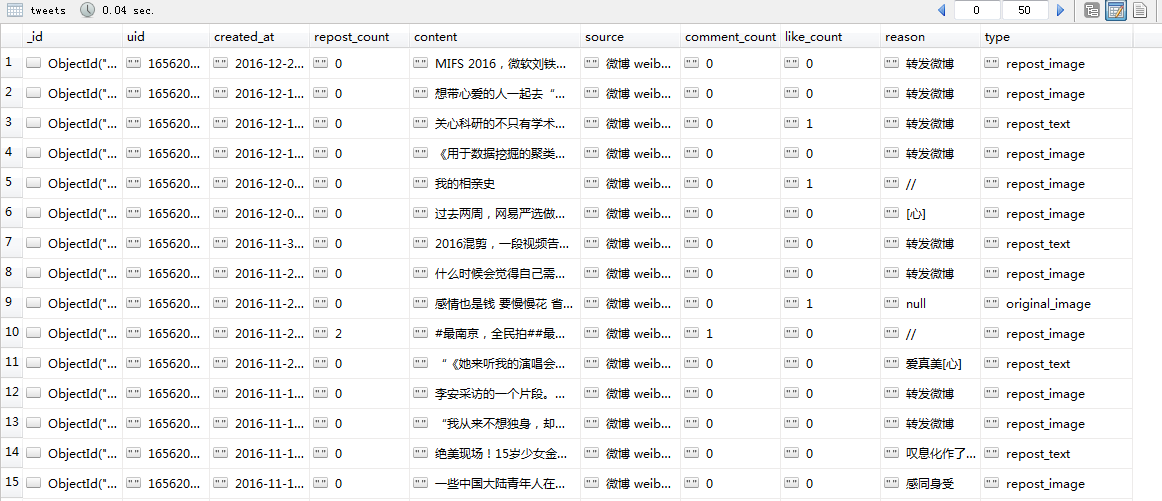
4.getUserTweets获取用户微博信息
1 | uid:用户ID |
存储结果
调用main.py文件会得到四个结果,截图如下:
由于博主时间有限,目前该爬虫正处于成长阶段,部分功能尚未完善,需进一步优化,如果感兴趣,可关注博主的微博@拾毅者,或是移步Github 关注本爬虫SinaWSpider的最新动态。最后,祝大家圣诞节日快乐吧,期待下个路口遇见你。