在上一篇文章豆瓣13万电影数据统计与分析里面,笔者对豆瓣的电影数据进行了基本的统计和分析,通过数据我们对电影的整体情况有了初步认识。为了进一步利用好这份数据,本文将开启本博客新的知识领域——知识图谱。基于这13w豆瓣电影数据,提取出图谱数据,并以此建立图谱数据库,构建电影知识图谱。
数据准备
从豆瓣爬取下来的电影数据比较丰富,包括电影名称、上映日期、国家、语种、导演、演员、标签、豆瓣评分、投票数量等信息,为了构建图谱数据库,我们需要对这张表进行转换,将其改造成图谱数据的形式。原始数据movie信息包括:name、alias、year、regions、genres、languages、release_date、directors、actors、storyline、mins、tags等,接下来,我们将从这份数据中抽取出电影表、演员表、电影类型表、电影与类型关系表、演员与电影关系表五张数据结构表(3张节点属性+2张关系)。
电影类型表
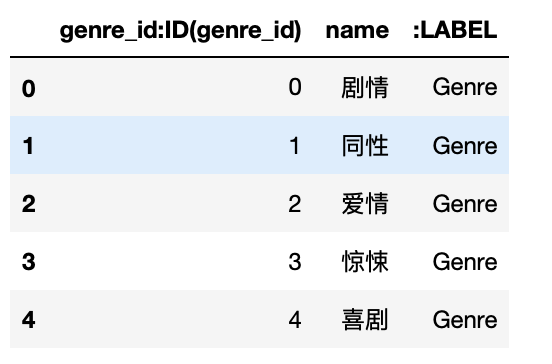
在爬取的豆瓣电影数据中,一部电影对应了多种类型,内容采用“/”进行连接,如“剧情/同性”。为了更好地表示电影与类型的关系,我们需要将类型抽取出来,做成单表genres.csv,最终的类型共54种。字段如下:
genre_id:ID(genre_id):类型IDname:电影类型名称:LABEL: 标记,取值为”Genre”
类型样例数据如下:
演员信息表
得到电影类型数据之后,接下来我们提取演员信息。演员人名也是从爬取的数据里面提取出来的,演员的个人信息从网上检索了一些,作为参考,后续继续补全。最后的演员表字段如下(actors.csv,10w+):
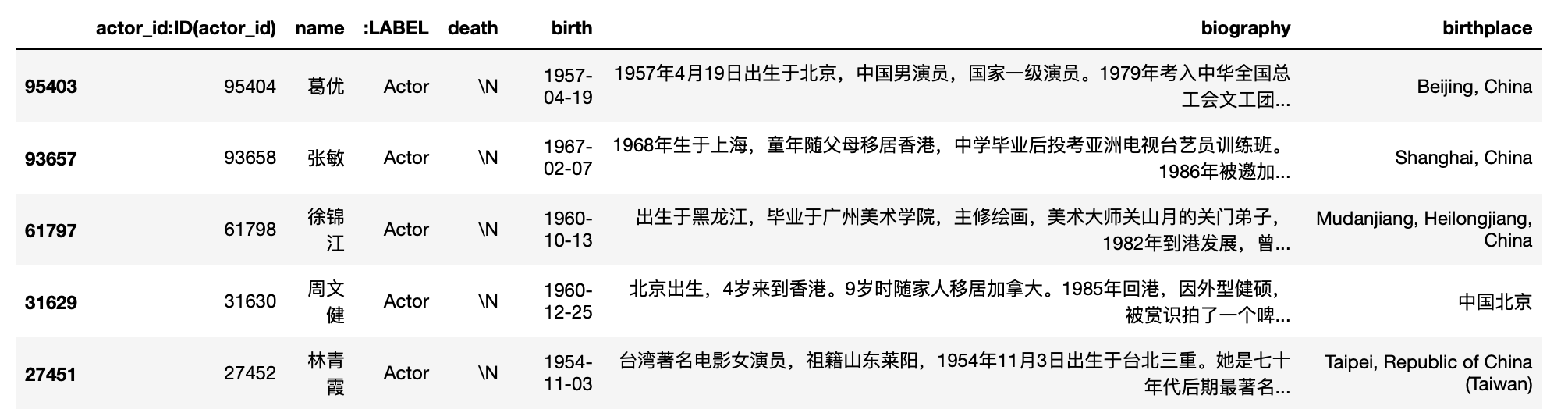
actor_id:ID(actor_id): 演员ID;name: 演员姓名;birth: 出生日期;death: 去世日期;biography: 个人介绍;birthplace: 出生日期;:LABEL: 演员表的标记,取值“Actor”。
下图是演员表的样例数据:
电影信息表
电影信息表基本保持原样,增加了电影表的标记:LABEL,便于neo4j图谱数据的识别,同时对原有的字段进行简单更换。如将douban_id作为movie_id,将name改成title等。电影表的字段如下(movies.csv):
movie_id:ID(movie_id): 电影IDtitle: 电影标题actors: 电影演员列表alias: 别名directors: 导演rating: 豆瓣评分douban_votes: 豆瓣投票人数genres: 电影类型languages: 电影语种mins: 电影时长regions: 发布区域release_date上映日期storyline:电影故事描述tags: 电影标签year:发行年份:LABEL: 电影表标记
样例数据如下:
电影-类型关系表
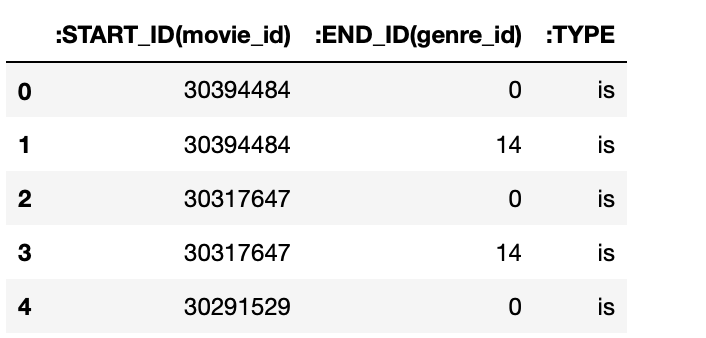
对于豆瓣电影数据,电影与类型的关系是one-vs-more,为此我们对每部电影建立电影与类型的关系表数据(29w+),结果如下:
演员-电影关系表
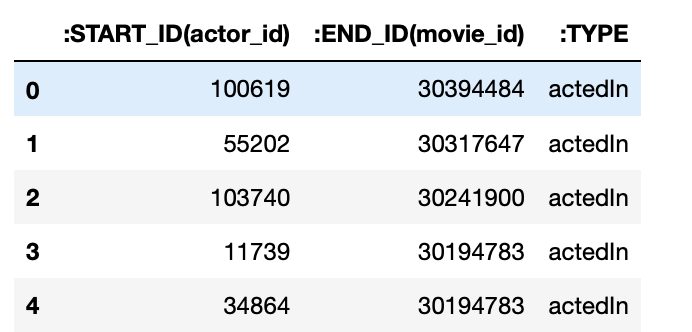
对于豆瓣电影数据,演员与电影的关系也是one-vs-more,为此我们对每个演员建立演员与电影的关系表数据(22w+)。结果如下:
基于neo4j构建图谱
上面五张表有三张属性表,两张关系表,接下来我们将这些数据输入到neo4j图谱数据库里面。关于neo4j,不了解的可以自行去官方网站里查看下,本文不做过多的介绍。neo4j导入数据的方式有多种,由于我们的电影数据有10w+,关系数据有百万,所以采用的是官方指定的neo4j-amin import方式。步骤如下:
1)首先将数据放入neo4j目录下的import目录下;
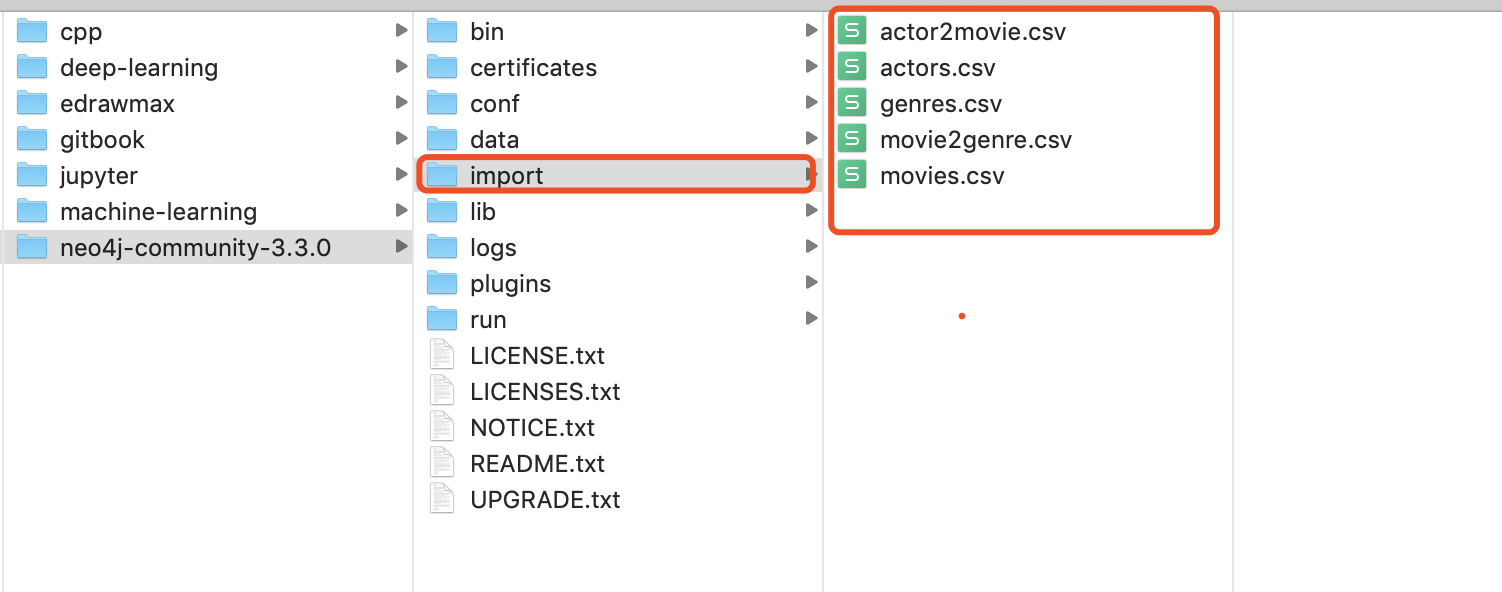
2)如果neo4j处于启动状态,则进入neo4j的bin目录下执行neo4j stop将其关闭。然后执行下面命令,将node和关系录入到图数据库中。
1 | neo4j-admin import --mode csv \ |
参数说明:
- id-type:将各个表的id数值类型进行初始化,上面设置的是INTEGER;
- nodes:表示的节点;
- relationships:表示的是关系表
- database: 表示的是创建的数据库,默认是graph.db,如果存在则无法创建,需要删除方可。
3)修改neo4j默认数据库。neo4j默认启动的图数据库为graph.db,因此如果创建了一个新的图数据库,直接启动neo4j是无法看到图数据库的相关信息,处理方式有多种,其一是在$NEO4J_HOME/conf/neo4j.conf中修改dbms.active_database参数。其二是将$NEO4J_HOME/data/database/目录下的graph.db文件换名,然后采用软连接将新库链接到graph.db上。
1 | cd $NEO4J_HOME/data/database |
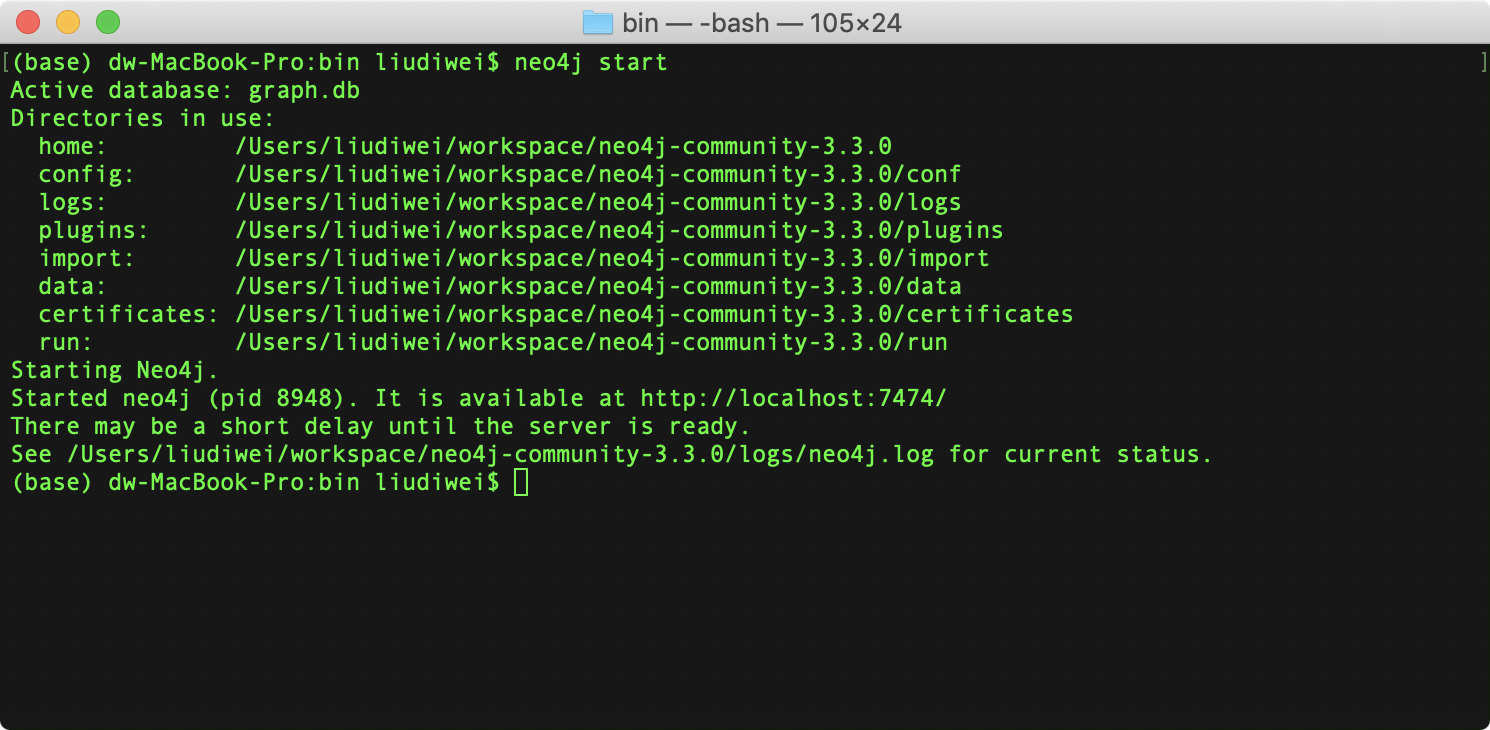
4)进入bin目录,采用neo4j start启动neo4j。
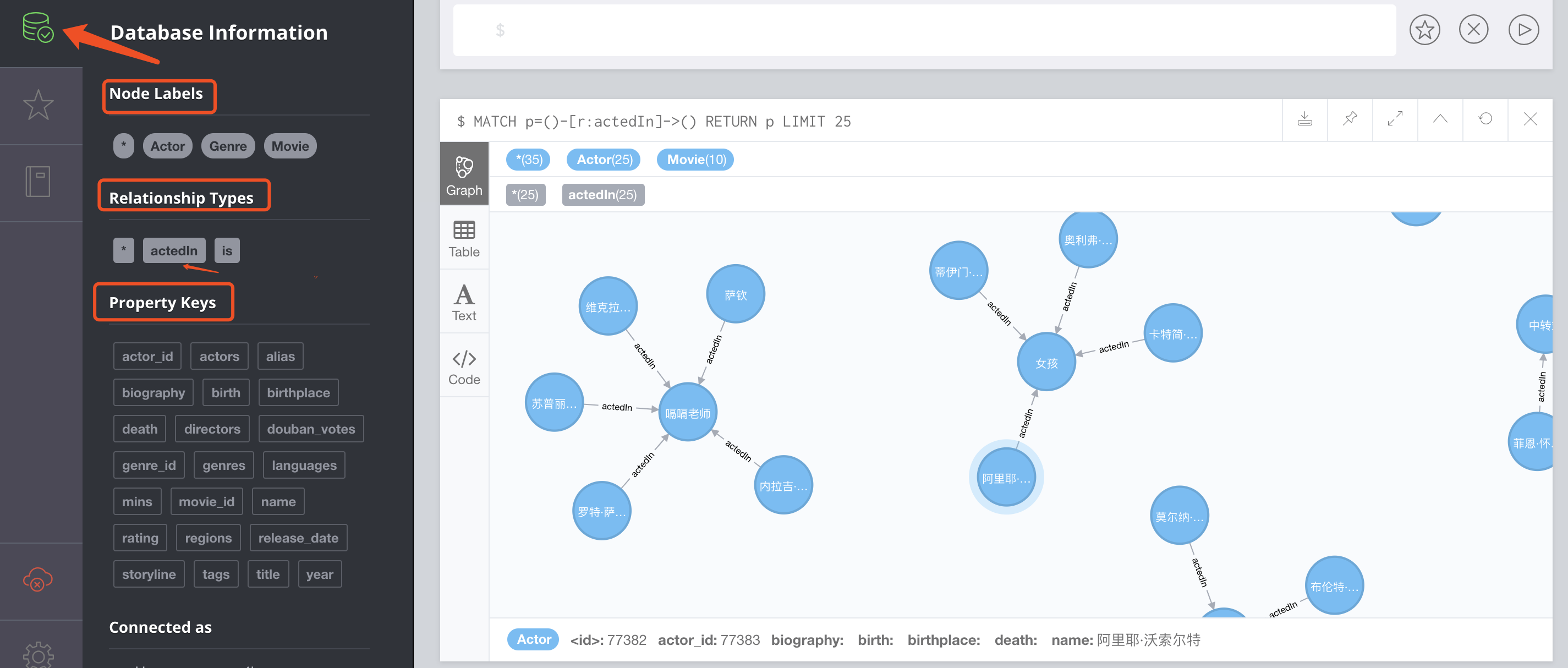
5)可视化结果查看。neo4j默认采用的是7474端口,当启动完成之后,我们可以在浏览器中输入http://localhost:7474/进入neo4j可视化界面,首先点击下图左上方的图标,然后选择一个relationship,即可查看图谱样例,如下:
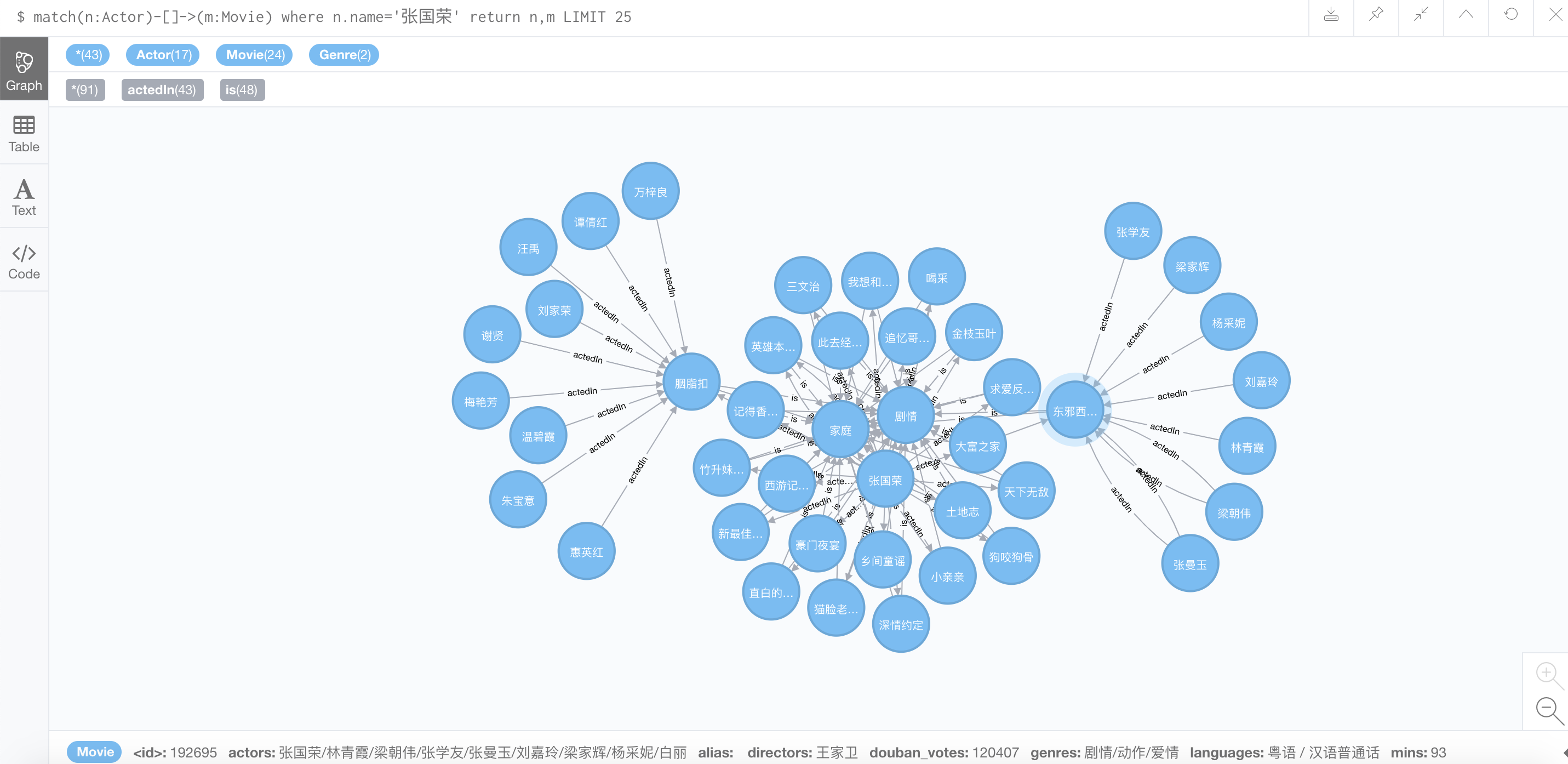
6)图谱搜索
通过neo4j图谱,我们可以搜索出很多有用的东西,比如通过下面的命令我们可以搜索到张国荣演过的电影(LIMIST 25Î),当我们双击东邪西毒时,还可以得到东邪西毒的相关演员:
1 | match(n:Actor)-[]->(m:Movie) where n.name='张国荣' return n,m LIMIT 25 |
OK,其他的demo这里就不展示了,感兴趣的可以玩一下neo4j。
Conclusion
本文主要以实践为主,根据已有的电影数据提取出neo4j需要的图谱节点数据和节点关系,整体上比较简单。值得注意的是,通过neo4j-admin import 方法来导入csv,表头名称需要格外注意,neo4j有其特定的表头识别能力。对于图中的节点关系,实验中的设计的比较简单,后续还会将director抽取出来,以此引入movie与director的关系。另外,为了进一步的将图谱应用起来,接下来将会实现一个基于图谱的QA问答功能,具体细节,我们下周再见。