倒腾豆瓣电影短评情感分析也有一阵时间了,一直抓着这个不放也不是个事,得赶紧腾出时间去总结下KG。本文算是笔者对情感分析的进阶篇,也是关于情感分类模型覆盖最全的文章。首先,从传统的特征提取方面对比了BOW、TF-IDF、N-Gram技术,并使用不同的机器学习算法构建了不同的子模型,然后又采用了Stacking模型融合技术对短评情感进行了进一步的探索,最后进阶到深度学习,构建神经网络模型进行文本分类。全文各个模型并不是参数最优,但也有一定的参考价值,因为针对不同的数据集,模型的预测结果都是不尽相同的。言归正传,下面一起来看看电影短评情感分析的结果吧!
往期回顾
首先介绍下笔者先前写的几篇关于电影短评的文章:第一篇文章介绍的是如何构建高质量的情感分析数据集,第二篇是采用MNB做的一个baseline模型,第三篇是数据集的原始来源。本文使用的数据集来自文章[1],整个训练集正负样本各220000条,测试集正负样本各24912条。
这三篇文章主要是情感分析初始篇,模型层面的东西基本上没有涉及。本篇则是从模型出发分析短评情感。在文章内容篇幅上,笔者将从以下几个大方向构建电影短评情感分析模型:
- 基于Bag-Of-Words特征的文本分类模型
- 基于TF-IDF特征的文本分类模型
- 基于Stacking模型融合的情感分析
- 基于深度学习的短评情感分析
基于Bag-Of-Words特征的文本分类模型
笔者首先对短评数据进行了分词,然后算出每个短评的bow特征,并在此基础上训练了LR、MMB、RF、GBDT四个模型,当然各个模型都没有进行很深程度的调优。从Table 1可以看出,bow-LR模型整体上预测结果最好,AUC达到了0.9399,其他预测指标也达到了0.87。
| 模型名称 | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| bow-LR | 0.868 | 0.87 | 0.87 | 0.87 | 0.9399 |
| bow-MNB | 0.865 | 0.86 | 0.86 | 0.86 | 0.9342 |
| bow-RF | 0.818 | 0.82 | 0.82 | 0.82 | 0.8902 |
| bow-GBDT | 0.7557 | 0.76 | 0.76 | 0.76 | 0.8535 |
核心代码如下:
1 | transformer = CountVectorizer(analyzer=process.process_line) |
基于TF-IDF特征的文本分类
TF-IDF在文本处理中经常用到,至少在我的工作中是用到的较多,比如计算文本相似度的时候,比较简单而且常用的做法就是,先将句子的TF-IDF值算出来,然后根据欧式距离计算相似度。TF-IDF(词频-逆文档频率)技术,是文本向量化的常用做法,从文本中提取特征以供后续的算法使用。
在这一小节里,特征方面最开始尝试了基于word的tfidf,然后又尝试了word-ngram-tfidf,后来将word-level替换成char-level,基于char构建n-gram。当然,关于ngram的n究竟该怎么取,也是一个值得考量的因子,读者如有兴趣,可以尝试下3-gram to 6-gram。针对不同的特征,笔者对比了LR、RF、MNB、GBDT四个算法,四个模型除了RF和GBDT是基于tree的,其他的都是不同类型的,以示区分。共训练了12个模型,各个模型的结果如Table 2所示。
| 模型名称 | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| word-level-tfidf-LR | 0.872 | 0.87 | 0.87 | 0.87 | 0.9438 |
| word-level-tfidf-MNB | 0.862 | 0.86 | 0.86 | 0.86 | 0.9394 |
| word-level-tfidf-RF | 0.8219 | 0.82 | 0.82 | 0.82 | 0.8930 |
| word-level-tfidf-GBDT | 0.723 | 0.72 | 0.72 | 0.71 | 0.8183 |
| word-ngram-tfidf-LR | 0.8724 | 0.87 | 0.87 | 0.87 | 0.9439 |
| word-ngram-tfidf-MNB | 0.8642 | 0.86 | 0.86 | 0.86 | 0.9399 |
| word-ngram-tfidf-RF | 0.8212 | 0.82 | 0.82 | 0.82 | 0.8925 |
| word-ngram-tfidf-GBDT | 0.7630 | 0.77 | 0.76 | 0.76 | 0.8588 |
| char-ngram-tfidf-LR | 0.8866 | 0.89 | 0.89 | 0.89 | 0.9552 |
| char-ngram-tfidf-MNB | 0.8657 | 0.87 | 0.87 | 0.87 | 0.9410 |
| char-ngram-tfidf-RF | 0.8276 | 0.83 | 0.83 | 0.83 | 0.9009 |
| char-ngram-tfidf-GBDT | 0.7686 | 0.78 | 0.77 | 0.77 | 0.8613 |
让笔者比较意外的是,GBDT和RF的结果居然比LR还要差,不过稍微想了下也感觉正常,主要是没有经过细致的调参。在上述12个模型中,基于char的ngram特征结合LR,测试集的预测结果,不管是precision还是recall、F1,都达到了0.89,AUC也高达0.9552,相对其他的模型,确实要高出一筹。说明一下,上述模型中基于word的ngram取得是[1,2,3]-gram,基于char的ngram是[2,3]-gram。
在算法上,笔者没有尝试SVM、xgboost、LightGBM等大众算法,一方面是SVM训练的速度过慢;另一方面是后面还会构建其他算法模型,传统的仅做参考吧。不过,虽然现在很多企业都转向了做深度学习模型,但传统的特征提取构建模型的方式还是值得学习一下的,毕竟知识掌握了就是自己的,缕清之后也就多了一份自信,没掌握的存放在电脑上的,那都是资料!!
基于Stacking模型融合的情感分类模型
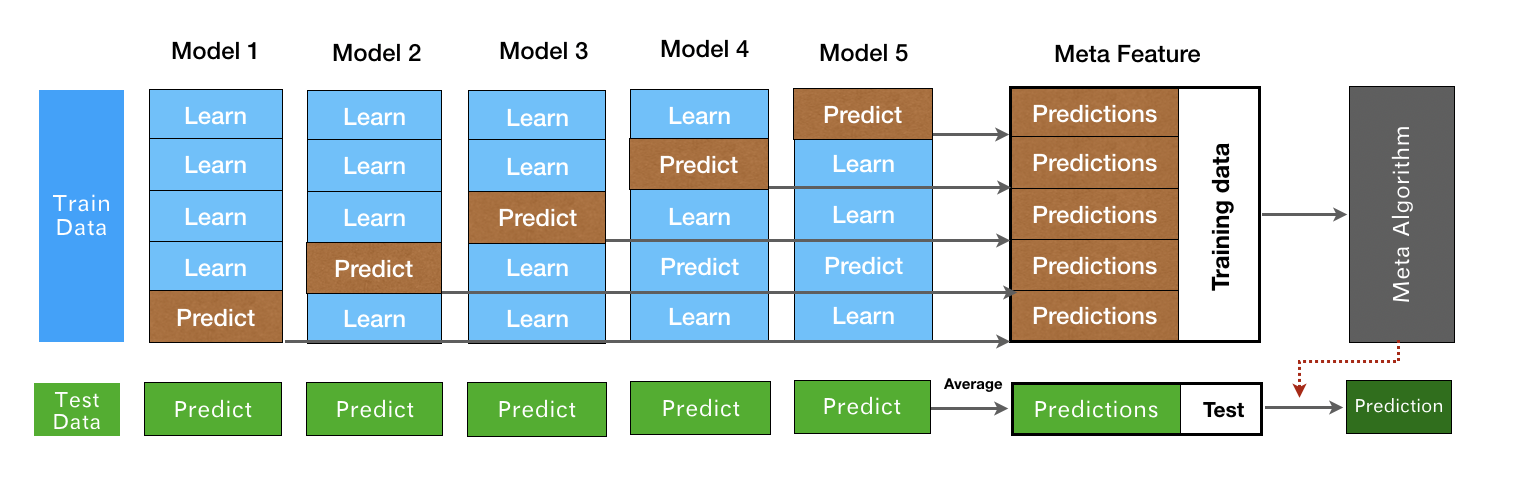
关于stacking融合技术,整个过程如Fig 1所示。首先将数据集划分为训练集和测试集,训练集主要用于sub-Model训练,训练方式有两种,一种基于cross-validation,一种是单纯的训练。两种方式具体的过程如下:
- Stacking-CV-Model:将训练集分成k份,在使用算法A进行交叉验证过程中,分别将每份作为测试集其余4分作为训练集训练分类模型,最后得到5个模型和5个测试集的预测结果,我们将算法A交叉验证得到的Out-Of-Fold结果作为一个特征集。如果有5个算法,每个算法得到的oof结果都是一个特征集,最后将其合并作为新的训练集(Meta Feature)。
- Stacking-Model:将训练集分成k份,假设有5个算法用于stacking子模型中,那么算法1采用第5份作为测试集,其余4份作为训练集,依此论推,算法2采用采用第4份作为测试机,算法3采用第3份作为测试集,算法4采用第2份作为测试集,算法1采用第5份作为测试机,其余作为训练集,最后将每个算法预测的测试集的结果合并,作为新的特征,即新的训练集(Meta Feature)。
如果有新的数据需要预测,那么都需要按照上述过程预测出新的特征,然后使用Meta algorithm预测出最终的结果。Stacking融合模型的代码已上传至github,仅供参考:https://github.com/csuldw/MachineLearning/blob/master/stacking/stacking.py
在短评情感分类中,关于stacking模型,笔者尝试了几个,如Table 3所示。从数据上可以看出,在特征都为bag-of-words的情况下,bow(lr+MNB+RF)+xgboost 融合的结果的确比Table 1的各个子模型预测的结果好。单独从Table 3来看,xgboost作为layer 2的Meta算法比LR作为meta Algorithm 要稍微好一些。而针对不同的特征,基于char的ngram仍然要高出bow和word-tfidf特征,其AUC达到了0.9592。
| 子模型 | Meta_Classifier | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|---|
| char-ngram-tfidf(lr+MNB+RF) | LR | 0.8830 | 0.88 | 0.88 | 0.88 | 0.9539 |
| char-ngram-tfidf(lr+MNB+RF) | xgboost | 0.8934 | 0.89 | 0.89 | 0.89 | 0.9592 |
| bow(lr+MNB+RF) | xgboost | 0.8751 | 0.89 | 0.88 | 0.88 | 0.9444 |
| word-tfidf(lr+MNB+RF) | xgboost | 0.8739 | 0.87 | 0.87 | 0.87 | 0.9465 |
基于深度学习的情感分析
上面采用了传统机器学习方法构建了文本分类模型,接下来将使用深度学习技术进行文本分类。至于两者到底谁更好,我们大可不必太过较真。记得去年公司内部的多语言情感分类比赛,第一名是将BERT、fastText与传统机器学习算法进行融合而构建的stacking模型,第二名则是采用纯粹的传统机器学习方法进行融合。比赛当中,对数据的处理真的比算法更重要,有时候看起不起眼的算法,只要特征工程做的好,结果都是出乎意料的。说这些并不是指深度学习不行,只是想让大家以客观的心态去看待它,不要将其神话了。对于文本分类,之前使用比较多的深度学习算法还属RNN,比如LSTM、GRU等。在BERT出来之后,对文本分类的精度又提升了一个level。笔者在做情感分析的时候,并没有尝试去使用BERT算法,仅仅是将深度学习模型框架搭建了起来,后续要使用的话,直接调用就行了!关于深度学习模型的调参,笔者也没有花太多的时间,主要是在Mac上训练一个网络速度太慢了,一个LSTM,跑几十万的训练数据,一个epoch差不多20多分钟,整个模型训练下来也要好几个小时,真的是耗不起!基于LSTM的模型框架Fig 2所示:
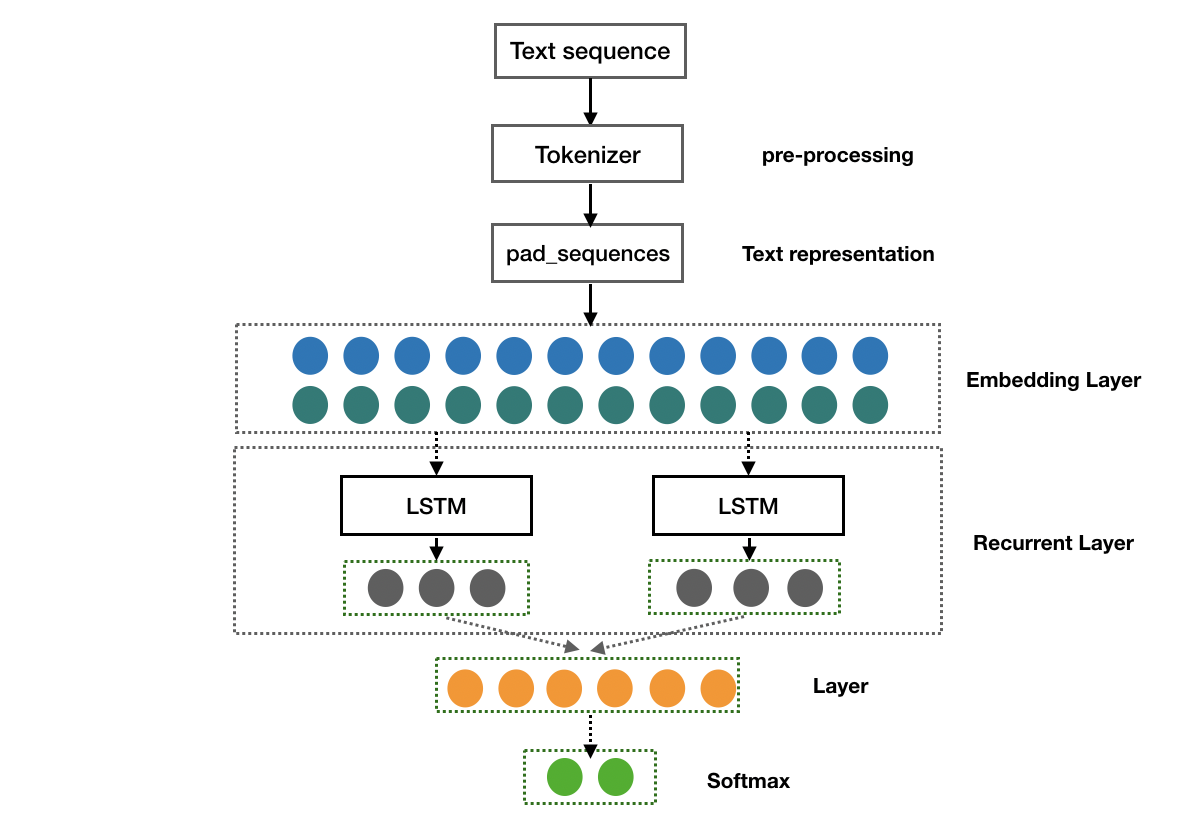
下面是笔者采用训练LSTM的核心代码(人生苦短,我用keras, v2.2.5),注意一下,这里采用了多分类的方式来做二分类,所以调用的是categorical_crossentropy.
1 | def train_model(X_train, y_train, X_test, y_test, n_words, batch_size, n_class=2): |
LSTM Model结构与参数数量如下:
1 | Model: "sequential_1" |
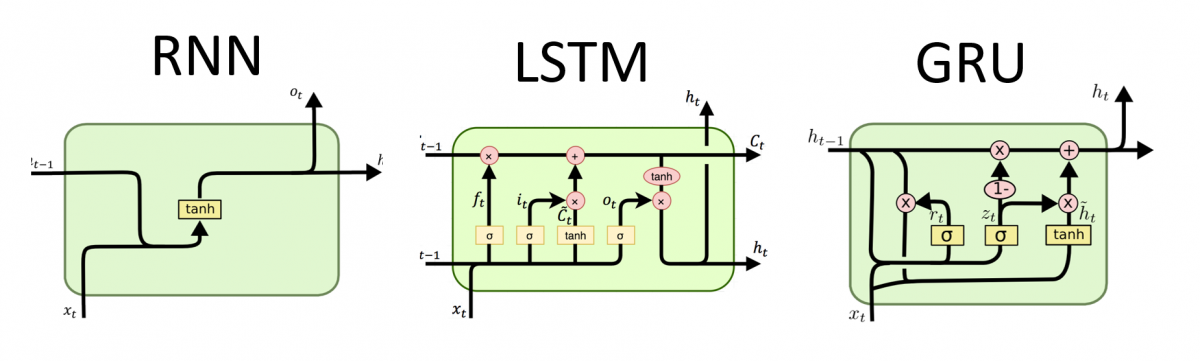
关于LSTM算法,这里不扩展了,感兴趣的童鞋可以参考下这篇文章Understanding LSTM Networks 。其内部结构如Fig 3 (中)所示,:
最终的模型预测结果如Table 4所示,在没有细致的调参情况下,LSTM模型的预测能力与上述传统的机器学习模型相差不大,GRU则与LSTM几乎持平:
| 模型名称 | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| LSTM-Model | 0.8685 | 0.87 | 0.87 | 0.87 | 0.9392 |
| GRU-Model | 0.8685 | 0.87 | 0.88 | 0.87 | 0.9404 |
| BiLSTM-Model | 0.8660 | 0.87 | 0.87 | 0.87 | 0.9380 |
上面只是简单的采用了LSTM和GRU来构建深度学习模型,针对分类任务,还有很多的方法可以实施。比如基于BERT预训练模型构建分类模型,或是CNN、fastText等,亦或是不同的深度网络结构,都可以用来优化模型的最终预测性能。另外,我们还可以将深度学习模型与传统的机器学习模型进行融合,构建基于深度学习和机器学习的stacking模型等等等等。当然,只追求模型的种类是绝对不行的,要深入到一个模型里面,将参数调制最优,才是学习之根本。比如深度学习模型,模型何时会收敛,如何尽量避免过拟合等等,都是一大学问。读者如有相关的问题,可以关注笔者的公众号[斗码小院],在后台或是文章中留言都可以。
结束语
本文针对豆瓣电影短评数据集,构建了四大分类模型:基于BOW特征的分类模型、基于TF-IDF特征的分类模型、基于Stacking模型融合技术的情感分类模型、基于深度学习的短评情感分析模型,共训练了20+个文本分类模型,其中传统的基于char-level-ngram-tfidf特征构建的模型,在相同的算法下,不亚于其他的word-level特征。在深度学习模型上,由于一个模型训练的时间过长,笔者并未花费太多的时间去优化。后续如果有新的进展,也会第一时间在本文的留言栏中说明。OK,关于情感分析,就到此为止吧,感谢各位读者的捧场!需要数据集的童鞋可关注[斗码小院]公众号,回复”情感分析数据集”即可。
本文的所有代码已上传至GitHub:https://github.com/csuldw/comment-sentiment-analysis,代码如有错误,还望读者指出,多谢!