在前面的Perceptron - 原理与实现一文中介绍了神经网络的基础算法,通过该文我们初步了解了感知机的原理以及实现。本文将介绍神经网络以及训练网络使用的Backpropagation(反向传播)算法,进一步为学习深度学习打好基础。阅读之前,先说明一下,由于推导过程公式较多,在编辑过程中可能出现个别差错,如有读者发现存在纰漏,还请E-mail告知,多谢!
神经元
提到神经网络,首先引入一下神经元的概念。神经元和感知器在本质上是一样的,不同之处就是两者的激活函数不一样,感知器使用的是符号函数,而神经元通常使用的则是sigmoid函数。关于sigmoid函数,可以参考之前的Logistic Regression Theory一文,这里就不多描述了。
神经网络定义
神经网络是按照一定规则连接起来的多个神经元。神经网络按照层级来布局神经元。最左边的层叫做输入层(input layer),主要负责接收输入数据;最右边的层叫输出层(output layer),可以从这一层获取神经网络输出数据。输入层与输出层之间的层叫做隐藏层,可以包含多个隐藏层,之所以叫做隐藏层,是因为它们对于外部来说是不可见的。神经网络的特征如下:
- 位于同一层的各个神经元没有任何连接。
- 位于第N层的每个神经元都与第N-1层的所有神经元相连,也就是全连接(Full Connection),第N-1层神经元的输出就是第N层神经元的输入。
- 全连接的每个连接都有一个权值。
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
基本函数
在本文,推导过程中值得注意的几个要点:
- 激活函数:sigmoid
- 误差函数:平方误差
- 优化方法:梯度下降,降低误差大的网络的权值,增加误差小的网络的权值。
下面先来介绍几个在神经网络反向传播算法的推导过程中用到的几个函数:
1.Network function(网络函数)
The network is a particular implementation of a composite function from input to output space, which we call the network function.
$$
h(x)=w^T x = \sum_{i=1}^{n} w_i x_i
\tag{1} \label{1}
$$
2.Activation function(激活函数)
本文使用的激活函数为Sigmoid函数:
$$
y=f(z)=\frac{1}{1+e^{-z}}
\tag{2} \label{2}
$$
3.Error function:(误差函数)
采用平方误差:
$$
E = \frac{1}{2} \sum_{i=1}^{n}\left[ t_i - y_i\right] ^2
\tag{3} \label{3}
$$
其中$t_i$为真实值,$y_i$为计算值,等于$f(h(x_i)) $.下面我们通过BP算法来模拟整个神经网络的计算过程。
反向传播算法用于找出误差函数的局部最小值,网络首先会随机地初始化各个权值。在计算上,通常会使用误差函数的梯度来修正权值。我们的任务就是递归地计算梯度。
首先,我们知道每个神经元都是一个感知器,对于输入层而言,$i1$和$i2$直接获取得到$x_i$的两个值,对于隐藏层和输出层,它们的每个神经元都是上一层的一个全连接,即:
$$h(x) = \sum_{i=1}^{n} w_i x_i$$
原理推导
前向传播
首先,我们来看看下面这张图:

上图展示的是一个经典的三层神经网络,包括输入层、隐藏层、输出层。为了体现一般性,现在我们用数学语言进行描述:
给定一个训练集$\{(x_1, t_1), (x_2, t_2), …, (x_n, t_n)\}$,目标变量$t_i$的取值可以有多个,其中$x_i$是一个$m$维向量(对应输入层的$m$个神经元),表达式为$x_i=(x_{i1}, x_{i2},…, x_{im})$。我们将输入层、隐藏层、输出层合并在一起,就形成了一个network。在这个network里,除输入层外,其他层上的每个神经元都是上一层神经元的全连接,不同的是全连接的权值不一样。现在,我们需要通过训练,来求出各个神经元的权重值,也就是$w$。
那么现在的问题是,这些权值应该如何计算呢?
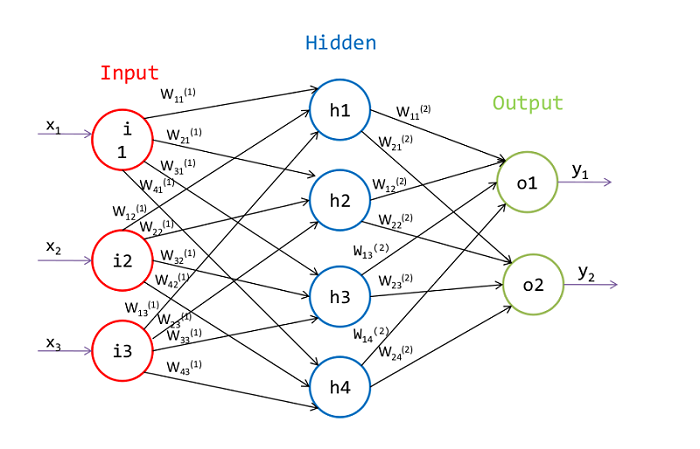
刚刚说到,除输入层外,其他层上的每个神经元都是上一层神经元的全连接,比如隐藏层$h1$,是隐藏层的第一个神经元,它的输出值是输入层的全连接,即:
$$
h_1 = f(\vec{w}_{1}^{(1)}\centerdot\vec{x})
\tag{4}\label{4}
$$
$$
net_{1}^{(1)} = w_{11}^{(1)} x_1 + w_{12}^{(1)} x_2 + w_{13}^{(1)} x_3 + b_{1}^{(1)}
\tag{5}\label{5}
$$
其中$f$为$sigmoid$函数,$\vec{w}_{ij}^{(1)}$表示隐藏层的第$i$个节点与输入层的第$j$个节点的权重值,$b_{i}^{(1)}$表示第$i$个隐藏层全连接中的偏置,$x_i$为输入层的值,即样本的输入值。
类似的,可以计算出$h_2$、$h_3$、$h_4$。
$$
h_1 = f(w_{11}^{(1)} x_1 + w_{12}^{(1)} x_2 + w_{13}^{(1)} x_3 + b_{1}^{(1)}) \\
h_2 = f(w_{21}^{(1)} x_1 + w_{22}^{(1)} x_2 + w_{23}^{(1)} x_3 + b_{2}^{(1)}) \\
h_3 = f(w_{31}^{(1)} x_1 + w_{32}^{(1)} x_2 + w_{33}^{(1)} x_3 + b_{3}^{(1)}) \\
h_4 = f(w_{41}^{(1)} x_1 + w_{42}^{(1)} x_2 + w_{43}^{(1)} x_3 + b_{4}^{(1)})
$$
因此,我们可以将隐藏层表示为如下通式:
$$
\vec{h}=f(net^{(1)})=f(\vec{w}^{(1)}\cdot\vec{x})
\tag{6}\label{6}
$$
$$
\vec{w}^{(1)}=
\begin{bmatrix}
\vec{w}_{1}^{(1)} \\
\vec{w}_{2}^{(1)} \\
\vec{w}_{3}^{(1)} \\
\vec{w}_{4}^{(1)} \\
\end{bmatrix}=
\begin{bmatrix}
w_{11}^{(1)},w_{12}^{(1)},w_{13}^{(1)},b_{1}^{(1)} \\
w_{21}^{(1)},w_{22}^{(1)},w_{23}^{(1)},b_{2}^{(1)} \\
w_{31}^{(1)},w_{32}^{(1)},w_{33}^{(1)},b_{3}^{(1)} \\
w_{41}^{(1)},w_{42}^{(1)},w_{43}^{(1)},b_{4}^{(1)} \\
\end{bmatrix}
$$
对于输出层,也是同样的计算方式,只不过对于输出层而言,它们的输入为隐藏层的输出,即$\vec{h}$,输出层的表达式为:
$$
\vec{y}=f(\vec{w}^{(2)}\cdot\vec{h})
$$
$$
\vec{w}^{(2)}=
\begin{bmatrix}
\vec{w}_{1}^{(2)} \\
\vec{w}_{2}^{(2)} \\
\end{bmatrix}=
\begin{bmatrix}
w_{11}^{(2)},w_{12}^{(2)},w_{13}^{(2)}, w_{14}^{(2)},b_{1}^{(2)} \\
w_{21}^{(2)},w_{22}^{(2)},w_{23}^{(2)}, w_{24}^{(2)},b_{2}^{(2)} \\
\end{bmatrix}
$$
$$
y_1 = f(w_{11}^{(2)} h_1 + w_{12}^{(2)} h_2 + w_{13}^{(2)} h_3 + w_{13}^{(2)} h_4+ b_{1}^{(2)}) \\
y_2 = f(w_{21}^{(2)} h_1 + w_{22}^{(2)} h_2 + w_{23}^{(2)} h_3 + w_{13}^{(2)} h_4+ b_{2}^{(2)}) \\
$$
即:
$$
\vec{y}_i=f(net_i^{(2)})=f(\sum_{j=1} w_{ij}^{(2)}h_j + b_j^{(2)})
\tag{7}\label{7}
$$
上述部分属于feed-forward部分,从前往后依次计算出各个输出层,最后求得$y$。但是值得注意的是,这些权值还未知呢,计算权值还得继续往下看,接下来通过BP算法来逐步更新权值。
反向传播
首先,我们对所有的权值$w$,给定一个初始值, 然后根据前向传播的方式来计算出输出值$y$,为了评估此次训练模型是否合理,我们取网络所有输出层节点的误差平方和作为目标函数,对于样本$k$,其误差表达式为:
$$
E_{k} = \frac{1}{2} \sum_{j=1}^{output}\left [ t_j- y_j \right ] ^2
\tag{8}\label{8}
$$
有了目标函数之后,现在我们采用梯度下降来寻找最优解。
1)输出层
对于输出层节点,第$i$个输出节点与第$j$个隐藏节点的权值更新规则为:
$$
w_{ij}^{(2)}\gets w_{ij}^{(2)}-\eta\frac{\partial{E_k}}{\partial{w_{ij}}}
\tag{9}\label{9}
$$
其中$\eta$为学习率,由于$E_k$是$y_i$的函数,$y_i$是$net$的函数,$net$是$w_{ij}$的函数,如下图,根据链式求导法则,有:
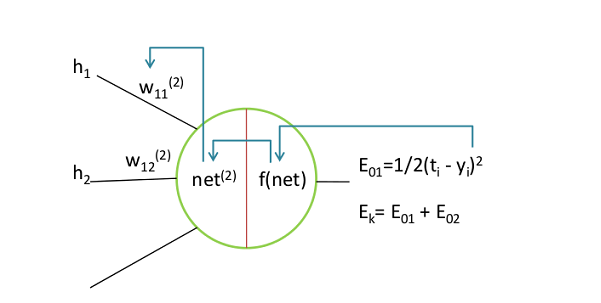
$$
\frac{\partial{E_k}}{\partial{w_{ij}}} = \frac{\partial{E_k}}{\partial{ y_i }} \frac{\partial{y_i}}{\partial{net_{i}}} \frac{\partial{net_{i}}}{\partial{w_{ij}}}
\tag{10}\label{10}
$$
根据上述公式,可以分别求出偏导数:
$$
\begin{align}
\frac{\partial{E_k}}{\partial{y_i}}
&=\frac{\partial}{\partial{y_i}} \left [\frac{1}{2}\sum_{j}^{outputs}(t_j-y_j)^2 \right ] \\
&=\frac{\partial}{\partial{y_i}} \left [\frac{1}{2}(t_j-y_j)^2 \right ]_{j=i} + \frac{\partial}{\partial{y_i}} \left [\frac{1}{2}\sum_{j}^{outputs}(t_j-y_j)^2 \right ]_{\color{red}{j \neq i}} \\
&=\frac{\partial}{\partial{y_i}} \left [ \frac{1}{2}(t_i-y_i)^2 \right ] + 0\\
&=-(t_i-y_i)
\end{align}
$$
$$
\frac{\partial{y_i}}{\partial{net_{i}}} =y_i(1-y_i)
$$
$$
\frac{\partial{net_{i}}}{\partial{w_{ij}}} = h_j
$$
由此可得,
$$
\begin{align}
\frac{\partial{E_k}}{\partial{w_{ij}}} = -(t_i-y_i) \cdot y_i(1-y_i) \cdot h_j
\end{align}
\tag{11}\label{11}
$$
令$\delta_i=\frac{\partial{E_k}}{\partial{net_i}}=-(t_i-y_i) \cdot y_i(1-y_i)$,(表示误差项,实际上是网络的损失函数$E_{k}$对神经元输入网络的偏导数)则:
$$
w_{ij}^{(2)} = w_{ij}^{(2)} - \eta \delta_i h_j
\tag{12}\label{12}
$$
2)隐藏层
首先,对于隐藏层的任意一个神经元,输出层的每个神经单元的误差对其都有影响。因此,对于隐藏层第$i$个神经元,它与输入层的第$j$个神经元的权值更新规则为:
$$
w_{ij}^{(1)}\gets w_{ij}^{(1)}-\eta \color{red}{\frac{\partial{E_k}}{\partial{w_{ij}}}}
$$
接着由链式法则,我们对上面红色部分进行展开:
$$
\begin{align}
\frac{\partial{E_k}}{\partial{w_{ij}}}
&= \frac{ \partial{}}{\partial{w_{ij}}} \left ( \sum_s^{outputs} E_s \right ) \\
&= \sum_s^{outputs}
\frac{ \partial{ E_s }}{\partial{net^{(2)}_{s}}}
\frac{ \partial{ net^{(2)}_{s} }}{\partial{ net^{(1)}_{i} }}
\frac{ \partial{ net^{(1)}_{i} }}{\partial{w_{ij}}} \\
&= \sum_s^{outputs} \left ( -\delta_{s} \cdot
\frac{ \partial{ net^{(2)}_{s} }}{\partial{ net^{(1)}_{i} }}
\frac{ \partial{ net^{(1)}_{i} }}{\partial{w_{ij}}} \right ) \\
&= \sum_s^{outputs} \left ( -\delta_{s} \cdot
\frac{ \partial{ net^{(2)}_{s} }}{\partial{ h_{i} }}
\frac{ \partial{ h_{i} }}{\partial{ net^{(1)}_{i} }}
\frac{ \partial{ net^{(1)}_{i} }}{\partial{w_{ij}}} \right ) \\
&= \sum_s^{outputs} \left ( -\delta_{s} \cdot
w_{si} \cdot
\frac{ \partial{ h_{i} }}{\partial{ net^{(1)}_{i} }}
\frac{ \partial{ net^{(1)}_{i} }}{\partial{w_{ij}}} \right ) \\
&= \sum_s^{outputs} \left ( -\delta_{s} \cdot
w_{si} \cdot
h_i(1-h_i)\cdot
\frac{ \partial{ net^{(1)}_{i} }}{\partial{w_{ij}}} \right ) \\
&= \sum_s^{outputs} \left ( -\delta_{s}
w_{si}
h_i(1-h_i)
x_j \right ) \\
&= -h_i(1-h_i) \left ( \sum_s^{outputs} \delta_{s} w_{si} \right ) x_j
\end{align}
$$
带入到上式,得到隐藏层的权值更新公式:
$$
w_{ij}^{(1)} = w_{ij}^{(1)}+\eta h_i(1-h_i) \left ( \sum_s^{outputs} \delta_{s} w_{si} \right ) x_j
\tag{13}\label{13}
$$
令$\delta_i=\frac{\partial{E_k}}{\partial{net_i}}=-h_i(1-h_i) \left ( \sum_s \delta_{s} w_{si} \right ) $,则公式简化为:
$$
w_{ij}^{(1)} = w_{ij}^{(1)}- \eta \delta_i x_j
\tag{14}\label{14}
$$
权值更新归纳
通过BP推导,现在我们知道如何更新权值了,下面来总结一下。假定每个节点的误差项为$\delta_i$,不管是隐藏节点还是输出节点,其输出值统一使用$x_{j}$来表示,那么权值更新规则为:
$$
w_{ij} \gets w_{ij} - \eta \delta_i x_j
\tag{15} \label{15}
$$
当节点为输出层神经元时,
$$
\delta_i= - y_i(1-y_i)(t_i-y_i)
\tag{15-1} \label{15-1}
$$
当节点为隐藏层神经元时,
$$
\delta_i = - h_i(1-h_i) \left ( \sum_s \delta_{s} w_{si} \right )
\tag{15-2} \label{15-2}
$$
其中,$\delta_{i}$ 是节点的误差项,$y_{i}$是输出节点的输出值,$t_{i}$是样本$i$对应的目标值,$h_{i}$为隐藏节点的输出值。
Conclusion
在实际编码中,整个参数训练过程大致如下:
- 初始化权值;
- 根据前向传播算法计算出输出层的输出,并计算出误差;
- 判断误差是否小于某个阈值,
- 误差满足阈值条件,则终止训练;
- 误差太大,则使用反向传播来更新权值,并转至步骤2,循环执行。
OK,终于完成了BP算法的推导过程,说实在的,公式敲得真是累人,不过看着充满逻辑的公式,心里还真有点成就感。关于具体的例子,可参考A Step by Step Backpropagation Example一文。至此,深度学习的大门似乎已经慢慢打开了,接下来,开始探索深度学习更深层的奥秘吧!