在上一篇文章基于豆瓣电影数据构建知识图谱 里面,讲到如何采用Neo4j来构建电影图谱,并且掌握了Neo4j里面的初级查询功能(搜索实体属性、实体间的关系等)。接下来,将进入电影图谱问答系统的学习,通过知识库和知识图谱来构建电影问答系统。针对QA问答系统,由于笔者当前能力有限,本文仅介绍基于模板的知识库问答,讲解过程中如果有阐述不周之处,还请读者指出!下面,我们来看看如何对问题进行解析,并将图谱应用到电影问答系统。
往期回顾:
Introduction 本文的电影QA问答系统工作流程如Fig 1所示,当接受到一个问题之后,我们首先对问题进行解析,包括分词、词性标注、关键字提取等预处理操作,并根据训练好的分类模型对问题进行分类,得到问题所属类之后,再根据图谱知识库搜索答案。在整个工作流程中,知识库在上一篇文章已经构建好了,并且已经存储到neo4j中。本文的主要工作是从问题到答案,端到端的实现。重点在如何对问题进行解析和分类,其次是借助neo4j进行答案检索。
Fig 1.QA问答系统工作流程
问题解析 当用户提出一个问题:”张国荣演过哪些电影?”时,我们需要对文本数据进行处理。在这里可以采用jieba进行分词、词性标注等操作,然后提取关键字。比如上面的问句,通过jieba进行词性标注的结果会是什么样子的呢?结果如下:
['张国荣/nr', '演/v', '过/ug', '哪些/r', '电影/n']我们看到“张国荣”被标记为nr,属于人名,演是动词,后面还有一些其他的,得到这个结果之后,接下来该怎么处理呢?我们再看看Fig 1,当问题解析完之后,我们需要对问题进行分类。说到分类,就必须得有个训练模型才行!下面就是一个问题多分类模型。基于问题模板数据来训练问题分类模型。
基于NB的问题分类模型 在这个章节中,我们将采用简单的NB算法来训练我们的分类模型,感兴趣的童鞋可以试试其他的分类算法。
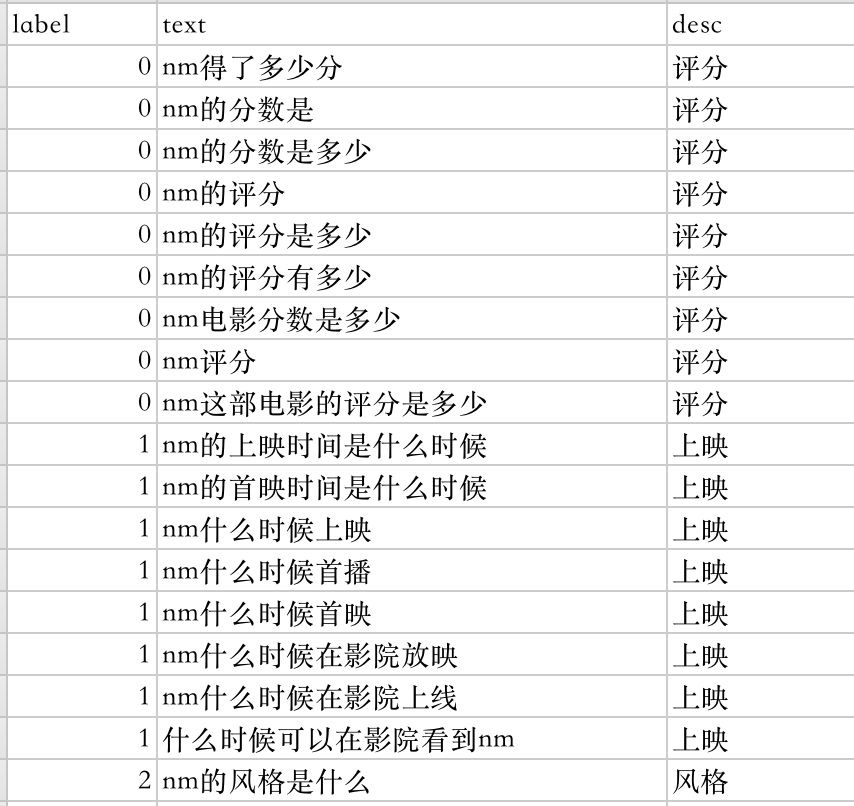
数据集 首先,来说说我们的数据集,样例数据如下,数据集包括三列,第一列是label(多分类),第二列是text(问题模板文本),第三列是描述(可忽略)。由于是实验demo,数据样例比较少,后续会根据需求不断扩展。
Fig 2.问题分类数据集样例
对于上面的数据集,可能有的童鞋会有点问题,nm表示什么?这里简单说一下,nm表示的电影的词性标注。在问题解析阶段,会对jieba的分词注入用户个人字典,每个电影的词性标注均为nm。这样,在分词之后,得到的结果也是nm。
例如:“红海行动讲的是什么故事?”,解析后的词与词性如下:
['红海行动/nm', '讲/v', '的/uj', '是/v', '什么/r', '故事/n']模型训练 关于模型部分,,其中用到了sklearn、pandas、jieba库,完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 """ Created on Sat Aug 24 14:38:04 2019 @author: liudiwei """ import jiebaimport pandas as pdfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.feature_extraction.text import TfidfVectorizerjieba.load_userdict("./data/userdict3.txt" ) class QuestionPrediction () : """ 问题预测: 采用NB进行多分类 数据集:template_train.csv """ def __init__ (self) : self.train_file = "./data/template_train.csv" self.train_x, self.train_y=self.read_train_data(self.train_file) self.model=self.train_model_NB() def read_train_data (self,template_train_file) : """ 可改写为读取一个文件 """ train_x=[] train_y=[] train_data = pd.read_csv(template_train_file) train_x = train_data["text" ].apply(lambda x: " " .join(list(jieba.cut(str(x))))).tolist() train_y = train_data["label" ].tolist() return train_x,train_y def train_model_NB (self) : """ 采用NB训练模板数据,用于问题分类到某个模板 """ X_train, y_train = self.train_x, self.train_y self.tv = TfidfVectorizer() train_data = self.tv.fit_transform(X_train).toarray() clf = MultinomialNB(alpha=0.01 ) clf.fit(train_data, y_train) return clf def predict (self,question) : """ 问题预测,返回结果为label """ question=[" " .join(list(jieba.cut(question)))] print("question:" , question) test_data=self.tv.transform(question).toarray() y_pred = self.model.predict(test_data)[0 ] return y_pred if __name__ == '__main__' : question_model=QuestionPrediction() print(question_model.predict("红海行动讲的是什么故事?" ))
通过read_train_data方法,我们得到的分词后的x_train如Fig 3的value字段所示。
Fig 3.训练数据样例
预测 单独执行上面的代码,最后返回的结果如Fig 4所示。最终将”红海行动讲的是什么故事?”划分到第三个类别。
Fig 4.问题预测结果
基于图谱的搜索 通过预测模型,我们可以将问题划分到某个模板中,接下来,再基于问题模板构造图谱搜索,比如上面的问题,我们将其划分到第三类问题:电影简介。接下来就可以采用py2neo连接neo4j图数据库,然后从图数据库中搜索出想要的答案。
1 2 3 4 5 6 7 8 def get_movie_introduction (self ) : movie_name = self .get_movie_name() cql = f"match(m:Movie)-[]->() where m.title=~'.*{movie_name}.*' return m.storyline" print(cql) answer = self .graph.run(cql)[0 ] final_answer = movie_name + "主要讲述了" + str(answer) + "!" return final_answer
最后得到的结果如下:
Fig 5.问题预测结果
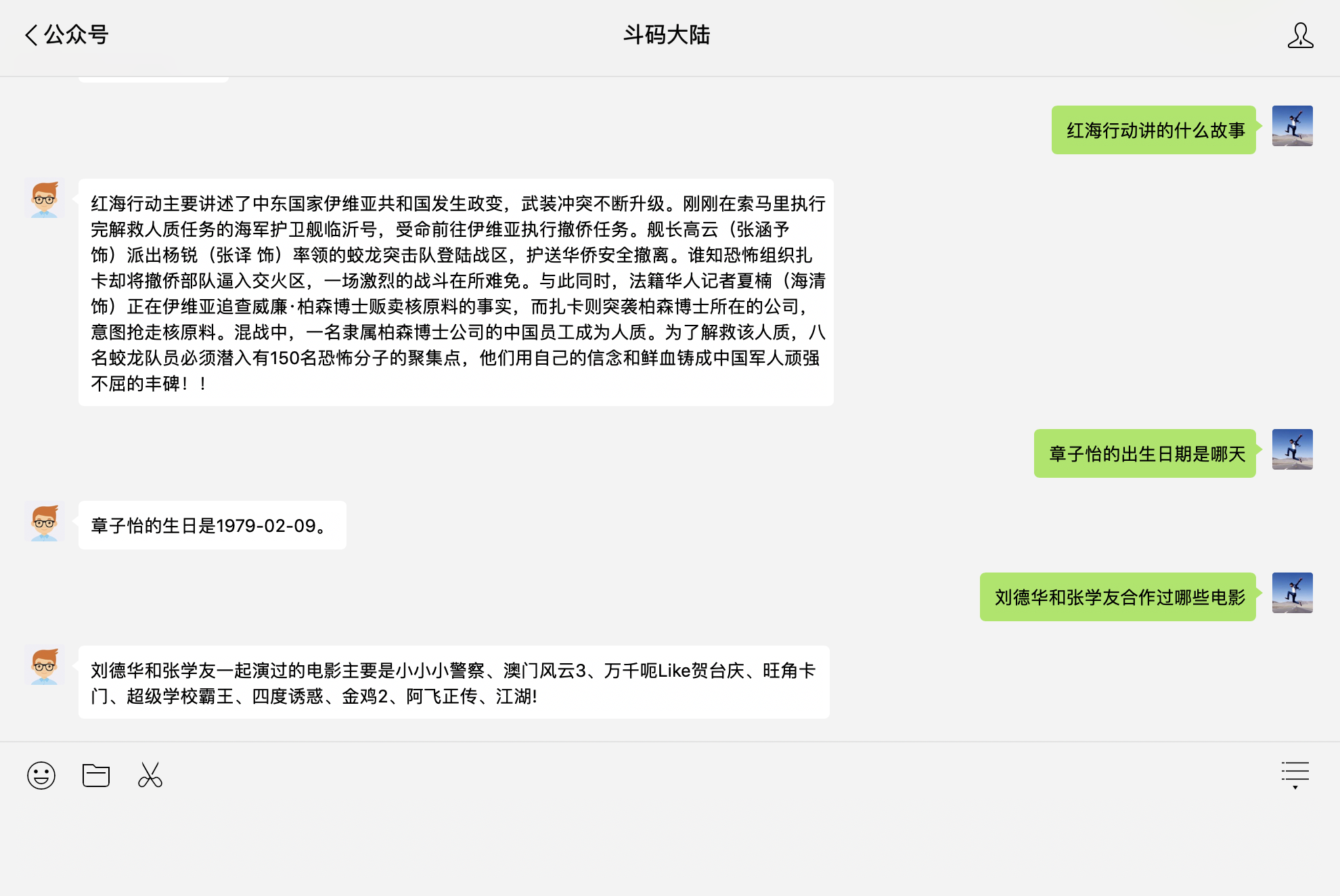
Conclusion 本文主要讲解了如何端到端的构建QA系统,方法虽然比较简单,但可以让读者了解整个工作流,对后续的学习也会有很好的帮助。为了将结果更好的展示出来,笔者将QA问答做成了服务,部署到了服务器中,并在服务器中搭建neo4j,构建电影图谱,最后将QA问答与微信公众号进行了集成,结果如Fig 6所示。感兴趣的童鞋,可以到公众号里【斗码大陆】体验一下,由于知识库不全,答非所问之事还请多多包涵哈。文中代码仅供参考,具体的源码等整理完之后再发布到github中吧。关于如何发布QA服务和微信公众号自动问答的集成,我们下期再见!
Fig 6.电影QA集成微信公众号
References
豆瓣13万电影数据统计与分析 基于豆瓣电影数据构建知识图谱 Knowledge Graph - Wikipedia Importing CSV Data into Neo4j