在前几篇文章,我们对豆瓣电影数据进行了一系列地处理、分析,并进行了QA问答建模等操作,有的童鞋可能对数据获取环节感兴趣。为此,本文将重点分享下我是如何构建豆瓣电影数据爬取模型,如何处理爬虫过程中遇到的问题,最终得到13w+电影数据加上28w+的影评数据。闲话少说,我们来看细节吧!
Scrapy框架介绍
本文介绍的爬虫模型是基于Scrapy框架构建的,Scrapy框架主要由五部分组成,如Fig 1所示,典型的东西南北中布局,分别为核心引擎Scrapy Engine、请求调度器Scheduler、网页下载器Downloader、数据提取与解析模块Spider以及数据存储Item Pipline。Scrapy这五个部分每部分都非常重要,同时还给了用户很大的设计空间,包括Middlemine的集成等。以前在编写微博数据爬虫模型的时候,采用的是原始urllib,编写代码确实耗费了不少时间。只是今非昔比,对于我们这种已经工作的时间非常宝贵的童鞋来说,确实耗不起了呀。
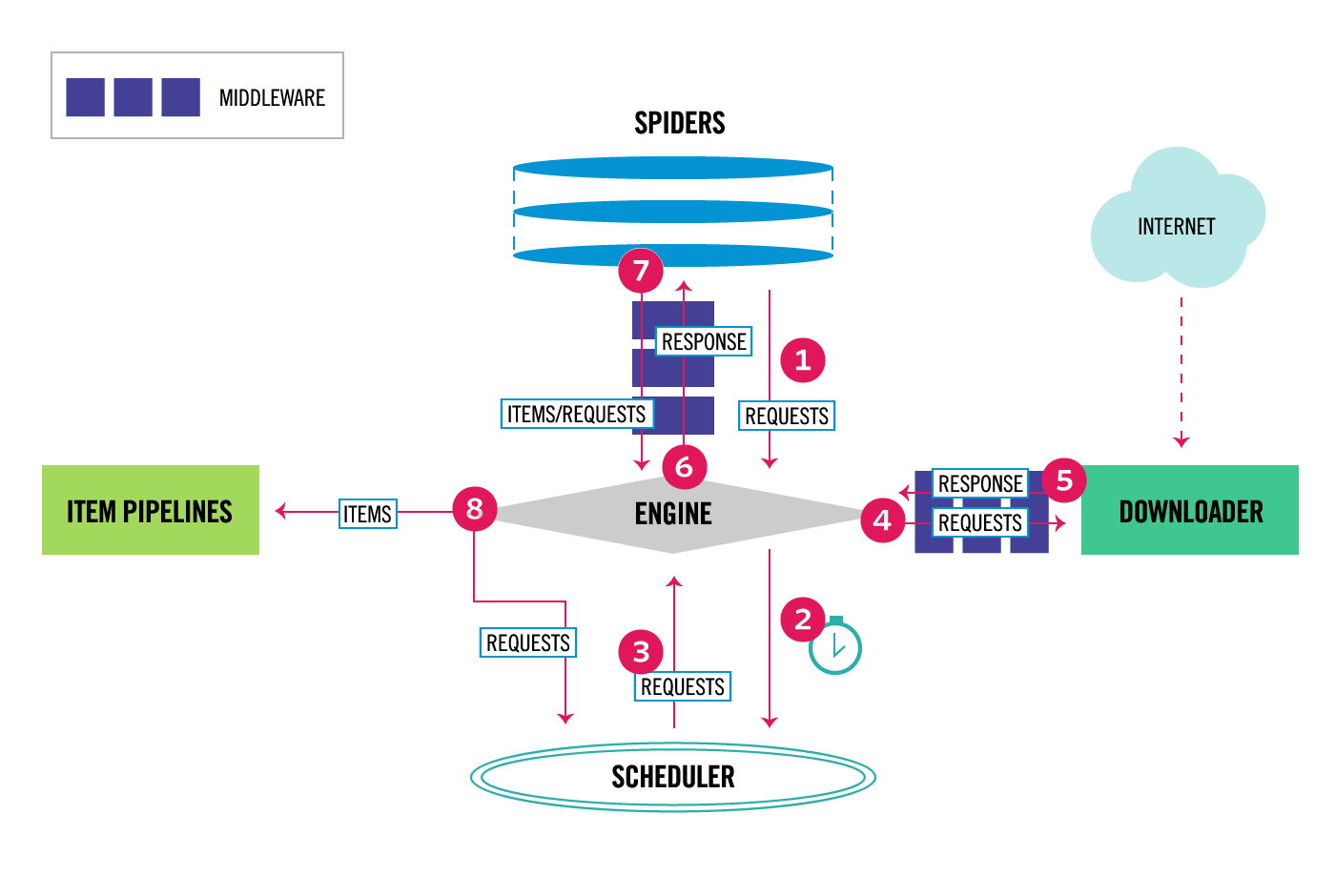
电影爬虫框架
豆瓣电影数据爬虫框架如Fig 2所示,整体上与Scrapy相差无几,只是在使用Scrapy时进行了自定义,在请求和数据处理方面都做了新的集成。当然,并不是原始创新啦,只是实现并优化了这部分功能。
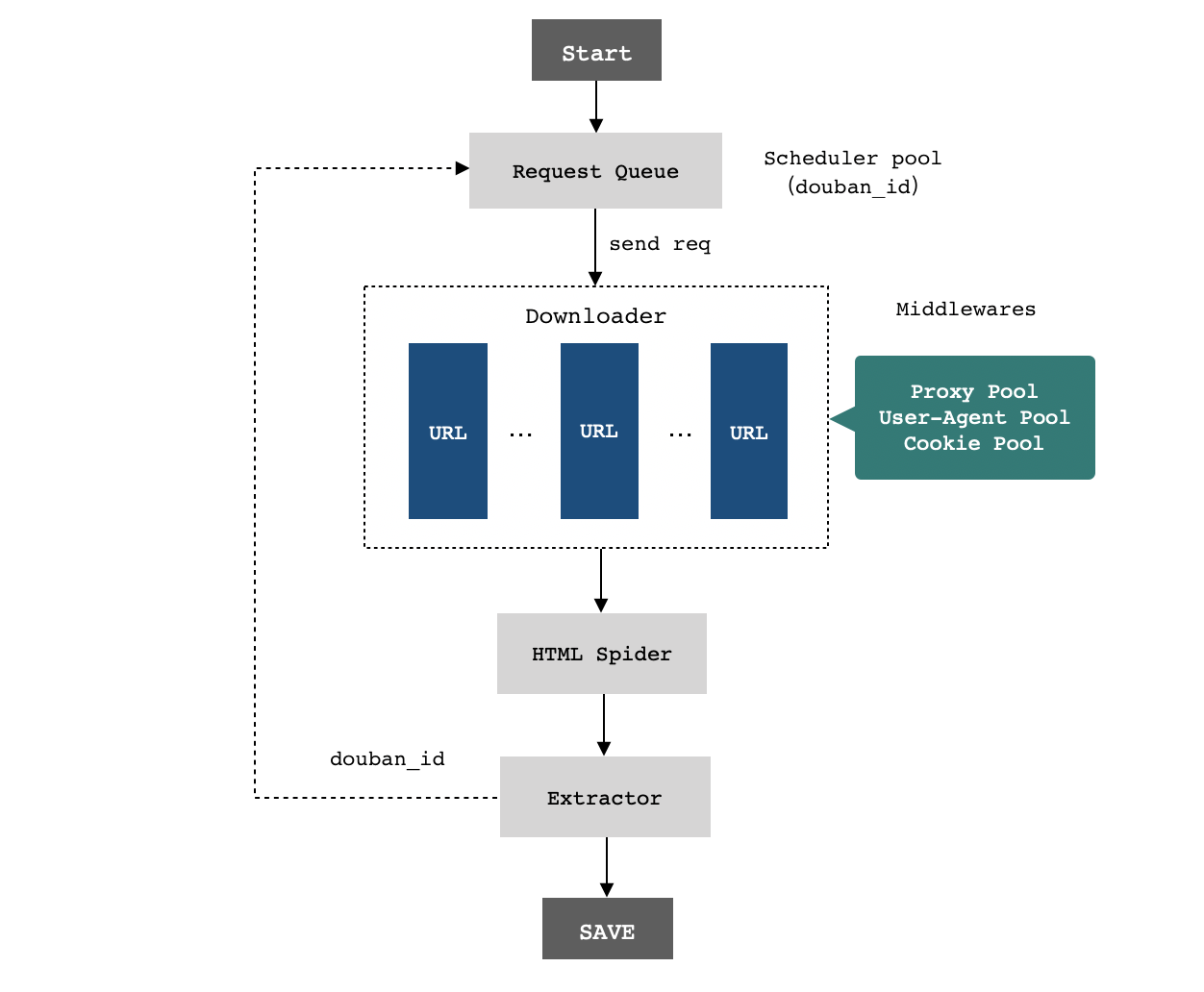
既然谈到了框架,大致介绍下爬取豆瓣电影数据时的思路。整个模型有三个spider,第一个是爬取douban_id的spider,爬虫引擎通过种子url发起请求,然后经spider将豆瓣ID(电影ID)解析出来写入到数据库中,然后基于新的douban_id继续爬取子ID页面的内容,依次循环。第二个爬虫是movie_spider,用于从数据库中读取没有爬取过页面详情的douban_id,通过spider爬取数据然后写入到MySQL数据库。第三个是爬取评论的comment_spider,根据douban_id来爬取电影评论数据。
三大核心
总的来说,对不需要登录的网站做数据爬取非常简单,因为只需要将网页提取出来,然后解析入库就OK了,从网页中发现的新种子又重新插入到请求队列中即可!通过爬虫的编写,自己对爬虫的了解也更深了。总结一下爬虫过程中需要注意的三大要点:
- 灵活选取初始种子。爬虫的第一个核心就是起始种子,如果我们的种子选的不好,或是路径非法,那么爬虫很可能就夭折了,所以一定要再三确认第一个请求url是否靠谱。
- 绕开反爬虫机制。第二个核心点是如何绕开反爬虫检测,爬虫三大奇技:UA、Cookie、Proxy。如果你没设置这些,导致小爬虫被检测出来了,那么你可能就祸害了一群人,因为这将直接导致你的外网IP会被ban一段时间,期间,你所在的网络区域都将受到这台服务器的限制,好在豆瓣没有这么狠,第二天就好了。在编写爬虫模型的过程中,我是怎么处理的呢?首先,User-Agent随机获取,并不是单一的UA,而是从User-Agent Pool大文件中读取。其次,针对性的改造Cookie,这得具体情况具体分析了。最后,动态切换Proxy代理,在每次发起请求时,都从MySQL里随机读取proxy ip,而关于MySQL的proxy数据,则通过额外的定时任务定期从代理商获取,获取时会将失效的代理置为无效。
- 优化爬虫性能。第三个核心要点是如何提高爬虫性能。首当其冲的就是多线程或是分布式,由于我是单机跑的,只用到了多线程。其次是对爬虫请求的去重,如果一个请求之前请求过了,那么下一次就不要浪费流量再次发送请求了!这个对于豆瓣数据的爬取真的很有用呀!
两大爬虫策略
Scrapy支持两种数据爬取策略,分别为: 深度优先和广度优先,通过参数进行配置即可。但是这个地方值得注意一下,如果你采用广度优先,当爬虫异常退出之后,不做任何改动重启,由于你的初始种子不变,这将致使你的爬虫很长一段时间没有新的数据入库,因为一直爬取的都是上一次爬取过的!反过来,如果你采用深度优先进行爬取,你也会碰到同样的影响,因为种子的顺序是不变的!这个问题也就是上面提到的三大核心的第一大点,解决方法就是:可以随机的从数据库获取初始种子,或者从数据库获取最后一次入库的请求id作为新的种子。
爬虫部署
在爬虫的部署上,也碰到一些问题,不过都得到了很好的解决。最开始的时候,没有设置proxy,只是加了Cookie和UA,结果没到一个小时,IP就被禁了,整个局域网内都需要登录豆瓣才能访问具体的电影了,爬到的电影ID(douban_id)大概1000+。第二天,改写了proxy代理的获取方式,最开始尝试的是从proxy ip文件中获取,然后需要隔一段时间更新下proxy文件内容,比较繁琐,就将手动修改文件的方法改成了自动修改,然后运行了一段时间之后,更新的代理无法得到实时的获取,于是又将这种方法pass了。最后,想到的是从数据库中查询有效代理,而数据库的代理通过定时模型进行更改,无效的IP则及时清理掉。通过这种方式部署之后,效果马上就上去了。将scrapy的并发数调制100都没问题。最开始每分钟可爬取100+的电影数据,到后面每分钟只能爬取60+左右,影响这个数据的因素大概是网速以及到后期很多电影都已经爬取完了,数据对比的次数增加了。代理修改期间,有试过编写代码获取免费代理进行爬取,结果太慢了,而且免费的都不好用哇,最后选择了付费的代理。
爬虫优化
通过上面的方式,已经可以很好的部署一个爬虫模型了。但是,速度还是比较慢!!!尤其是douban_id的爬取,到后面就太慢了,更新的速度简直让人看着难受,几乎是几s一个,让我这种有强迫症的看着真是一种煎熬呀!为此,仔细查看了点击豆瓣电影时请求的数据接口,意外的发现了一个接口,这里分享一下,大家千万万万别说是我告诉你们的,如下:
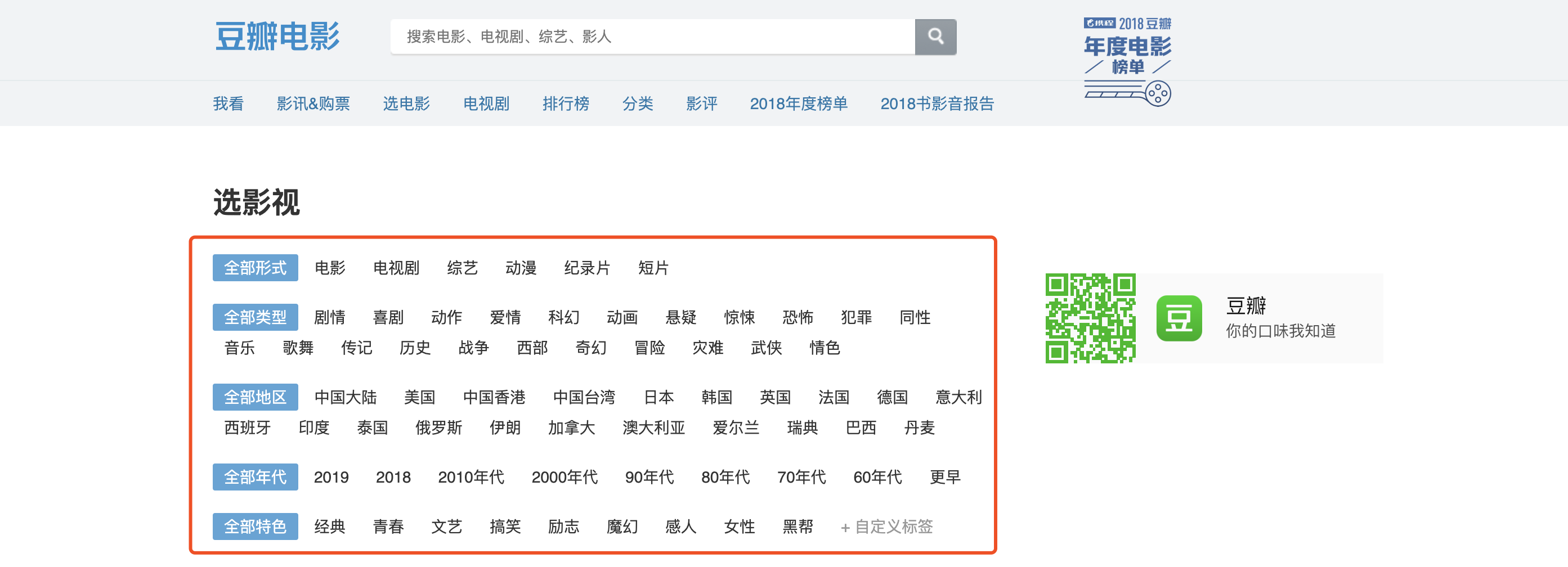
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=1&genres=剧情&countries=中国大陆通过这个接口,我就可以很轻松的得到douban_id了呀,数据样例Fig 3所示:

通过这个接口,我们再根据豆瓣电影的分类来实现豆瓣电影ID的获取,类型提取页面为https://movie.douban.com/tag/#/:
获取的代码片段如下(仅供参考):
1 | #按照分页来 |
结束语
OK,关于豆瓣影评数据爬取的细节内容,也差不多讲完了,代码层面涉及的不多,实现方面如果有疑问的可以公众号私聊我,希望对爬虫感兴趣的您有所帮助。至于代码何时开放出来,还请读者持续等待下,后续定会放到github中去的。有兴趣的,可以先关注下我的Github:csuldw,或者关注我的公众号【斗码大陆】吧!
