最近,在浏览towardsdatascience上面的机器学习相关文章的时候,无意间看到一篇关于异常检测的文章,刚好与自己的工作内容有点契合,文章讲解的是两种分析思路:第一种、PCA + Mahalanobis;第二种、AutoEncoder训练模型进行检测。兴奋之下,决定将这篇文章分享出来,如果内容有理解不当的地方,还请读者指出,深表感谢。
原文链接: How to use machine learning for anomaly detection and condition monitoring
本文,将介绍机器学习和统计分析几种不同的技术和应用,然后展示如何应用这些方法来解决特定场景:异常检测(anomaly detection)和状态监控(condition monitoring)。
Digital transformation, digitalization, Industry 4.0, etc….
这些都是你可能听过或读过的专业术语。然而,这些流行语背后的主要目标是使用技术和数据来提高生产力和效率。设备和传感器之间信息的连接和流动会产生大量的数据。关键因素在于能够使用这些大量的可用数据,并真正提取有用的信息,从而使降低成本、容量优化和宕机时间降至最低成为可能。这也是最近围绕机器学习和数据分析讨论其发挥作用的地方。
Anomaly detection
异常检测(或异常值检测)是对稀有物品、事件或观察结果的识别,这些物品、事件或观察结果与大多数数据存在显著差异,从而引起疑虑。通常,异常数据可以关联到某种问题或罕见事件,例如银行欺诈、医疗问题、结构缺陷、故障设备等。这种连接能够有趣地找出哪些数据点可以被视为异常,因为从业务角度来看,识别这些事件通常非常有趣。
关键目标:如何识别数据点是正常或是异常?简单的情况下,如下图所示,数据可视化可以比较直观的展示出来。
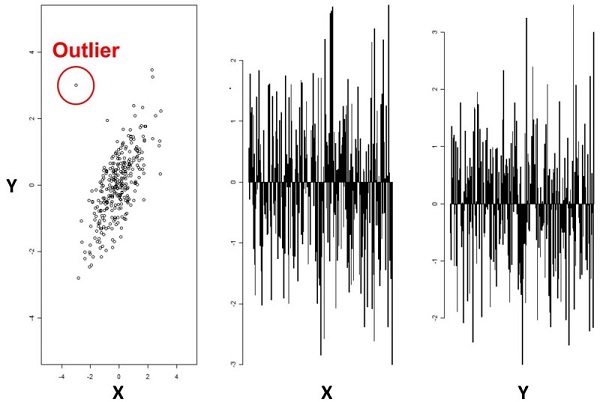
在二维空间(x和y)中,通过位于特定分布之外的数据点很直观地被我们识别为异常点。然而从右图来看,不可能直接根据一个变量就识别出异常值:正是X和Y变量的组合使得我们能够容易地识别异常值。当我们从两个变量放大到10-100个变量时,问题就变得非常复杂了,而这种场景经常出现在异常检测的实际应用当中。
Connection to condition monitoring
任何机器,无论是旋转机器(泵、压缩机、燃气轮机或蒸汽轮机等)还是非旋转机器(换热器、蒸馏塔、阀门等),最终都会达到不良的健康状态。这一点可能不是实际的故障或停机,而是设备不再以最佳状态运行。这表明可能需要一些维护行为来恢复最佳操作状态。简单地说,识别设备的“健康状态”是状态监控领域。
执行状态监控的最常见方法是查看机器上的每个传感器测量值,并对其施加最小和最大值进行限制。如果当前值在界限内,则机器正常。如果当前值超出界限,则机器不正常并发出警报。
设定硬编码告警阈值会产生大量的误报,即针对机器实际处于健康状态的情况发出报警。还可能漏报告警,也就是有问题但没有警报的情况。第一个问题不仅浪费时间和精力,而且浪费设备的可用性。第二个问题更为关键,因为它会导致相关维修成本的实际损失和生产损失。
这两个问题都是由同一个原因造成的:一个复杂设备的健康状况不能通过对每一个测量本身的分析来可靠地判断(如上图异常检测部分的图1所示)。我们更应该考虑多种测量方法的合并,以获得真实的情况。
Technical section
在不涉及更多技术方面的情况下,很难涵盖机器学习和异常检测统计分析的主题。我会避免太深入讲解理论背景(但会提供一些链接)。如果您对机器学习和统计分析的实际应用更感兴趣,例如状态监控,可跳到“状态监控用例”部分。
Approach 1: Multivariate statistical analysis
Dimensionality reduction using principal component analysis: PCA
处理高维数据通常具有挑战性,因此有几种方法可以减少变量的数量(降维)。其中一种技术就是主要成分分析(PCA),它将数据线性映射到低维空间,使数据在低维空间中的方差最大化。在实际应用中,需要构造了数据的协方差矩阵,并计算该矩阵的特征向量。对应于最大特征值(主分量)的特征向量可以用来重建原始数据方差较大的一部分。原来的特征空间已经减少(有一些数据丢失,但会保留最重要的方差)到几个特征向量所跨越的空间。
Multivariate anomaly detection
如上所述,为了在处理一个或两个变量时识别异常,数据可视化通常是一个好的起点。然而,当将此扩展到高维数据(在实际应用中经常是这样)时,这种方法变得越来越困难。幸运的是,多元统计数据起到了作用。
当处理一组数据点时,它们通常具有一定的分布(例如高斯分布)。为了更定量地检测异常,我们首先从数据点计算概率分布$p(x)$。然后,当一个新的例子$x$出现时,我们将$p(x)$与阈值$r$进行比较。如果$p(x)< r$,则将其视为异常。这是因为正常的例子倾向于有一个大的$p(x)$,而异常的例子倾向于有一个小的$p(x)$。
在状态监测的背景下,这很有趣,因为异常可以告诉我们被监测设备的“健康状态”:当设备接近故障时生成的数据,或次优操作,通常与“健康”设备的数据分布不同。
The Mahalanobis distance
如上所述,讨论数据点属于哪种分布的问题。第一步是找到采样点的质心或质心。直观地说,所讨论的点离这个质心越近,它就越有可能属于这个集合。然而,我们还需要知道集合是分布在大范围还是小范围,这样我们就可以决定距中心的给定距离是否值得注意。简单的方法是估计样本点到质心距离的标准偏差。通过将其插入正态分布,我们可以得出数据点属于同一分布的概率。
上述方法的缺点是,我们假设采样点以球形方式分布在质量中心周围。如果分布确定为非球形,例如椭球形,那么我们期望测试点属于集合的概率不仅取决于与质心的距离,而且取决于方向。在椭球体具有短轴的方向上,试验点必须更近,而在轴较长的方向上,试验点可以远离中心。在数学基础上,通过计算样本的协方差矩阵,可以估计出最能代表集合概率分布的椭球。Mahalanobis距离(md)是测试点到质量中心的距离除以试验点方向上的椭球宽度。
为了使用MD将测试点分类为属于n个类中的一个类,首先要估计每个类的协方差矩阵,通常基于已知属于每个类的样本。在我们的例子中,由于我们只对“正常”与“异常”进行分类感兴趣,因此我们使用只包含正常操作条件的训练数据来计算协方差矩阵。然后,给出一个测试样本,将MD计算为“正常”类,如果距离超过某个阈值,则将测试点分类为“异常”。
注意:使用MD意味着可以通过均值和协方差矩阵-进行推断,这只是正态分布的一个性质。在我们的例子中,不一定满足这个标准,因为输入变量可能不是正态分布的。不过我们还是可以试试,看看效果如何!
Approach 2: Artificial Neural Network
Autoencoder networks
第二种方法是使用自编码器神经网络。这是基于与上述统计分析相似的原则,但有一些细微的差异。
自编码器是一种人工神经网络,用于无监督地学习有效的数据编码。自动编码器的目的是学习一组数据的表示(编码),通常用于降维。与原边一起,学习重构边,其中自动编码器尝试从简约编码生成尽可能接近其原始输入的表示。
从结构上讲,AutoEncoder最简单的形式是一个前馈的、非重复性的神经网络,与许多单层感知器非常相似,多层感知器(MLP)具有一个输入层、一个输出层和一个或多个连接多层感知器的隐藏层-,但输出层具有相同数量的节点。作为输入层,目的是重建自己的输入。
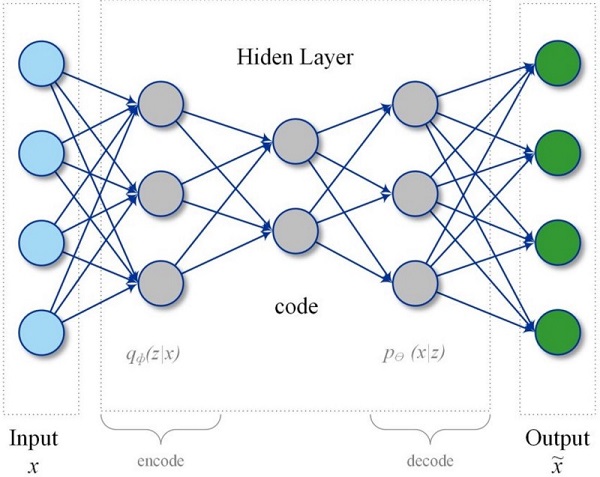
在异常检测和状态监测的背景下,基本思想是使用自动编码器网络将传感器读数“压缩”到较低的尺寸表示,从而捕获各种变量之间的相关性和相互作用。(基本上与PCA模型的原理相同,但这里我们也考虑了变量之间的非线性相互作用)。
然后,自动编码器网络接受表示“正常”操作状态的数据的训练,其目标是首先压缩然后重建输入变量。在降维过程中,网络学习各种变量之间的相互作用,并能在输出端将它们重新构造回原来的变量。主要想法是,随着被监测设备的退化,这将影响变量之间的相互作用(例如温度、压力、振动等的变化)。当这种情况发生时,人们将开始看到网络重新构造输入变量的错误增加。通过监测重建误差,人们可以得到被监测设备的“健康”指示,因为这种误差会随着设备的退化而增加。与第一种使用Mahalanobis距离的方法类似,我们这里使用重建误差的概率分布来确定数据点是正常的还是异常的。
Condition monitoring use-case: Gear bearing failure
在这一节中,我将使用上面描述的两种不同的方法,介绍一个用于状态监控的实际用例。由于我们与客户合作的大多数数据都不是公开的,我选择了展示NASA提供的两种数据方法,可以在这里下载。
在此用例中,目标是检测发动机上的齿轮轴承退化,并发出警告,允许采取预测措施以避免齿轮故障(例如,设备的计划维护/维修)。
Experimental details and data preparation:
三组数据分别由四个轴承组成,在恒负荷和运行条件下运行至失效。振动测量信号在轴承使用寿命期间提供给数据集,直至出现故障。在外座圈出现裂纹的1亿个循环后发生故障(有关实验的更多信息,请参阅下载页中的自述文件)。由设备一直运行直到出现故障,将前两天的运行数据当作训练数据,以代表正常和“健康”的设备。然后将导致轴承故障的时间的数据集的剩余部分用作测试数据,以评估不同的方法是否可以在故障之前检测轴承退化。
Approach 1 : PCA + Mahalanobis distance
正如本文“技术部分”中提及的那样,第一种方法是:首先进行主成分分析,然后计算马哈拉诺比距离(MD),以确定数据点是正常的或异常的(设备退化的迹象)。代表“健康”设备的训练数据的MD分布如下图所示。
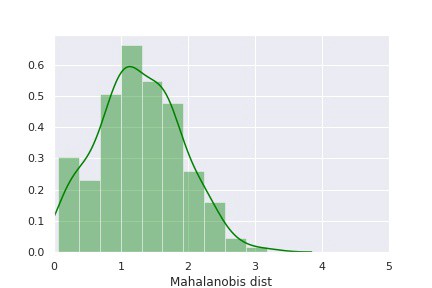
利用“健康”设备的MD分布,我们可以定义一个考虑异常的阈值。根据上述分布,我们可以将MD>3定义为异常。现在,这种检测设备退化的方法的评估包括计算测试集中所有数据点的MD,并将其与标记为异常的定义阈值进行比较。
Model evaluation on test data:
利用上述方法,我们计算了轴承失效前一段时间内试验数据的MD,如下图所示。
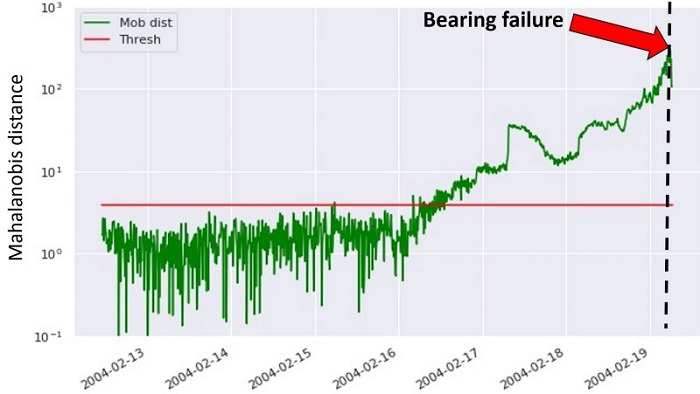
在上图中,绿点对应于计算得出的MD,而红线代表用于标记异常的定义阈值。轴承故障发生在数据集的末尾,用黑色虚线表示。这说明,第一种建模方法能够在实际故障发生前3天(MD超过阈值)检测到即将发生的设备故障。
我们现在可以使用第二种建模方法进行类似的练习,以评估哪些方法的性能优于其他方法。
Approach 2: Artificial Neural Network
如本文“技术部分”中更详细地解释的,第二种方法包括使用自动编码器神经网络来检测异常(通过增加网络的重建损失来识别)。与第一种方法类似,在这里我们使用代表“健康”设备的训练数据的模型输出分布来检测异常。训练数据重建损失(平均绝对误差)分布如下图所示:
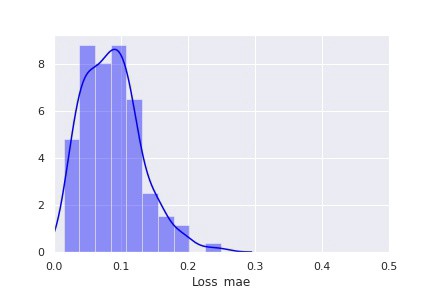
利用“健康”设备重建损失的分布,我们现在可以定义一个考虑异常的阈值。根据上述分布,我们可以将大于0.25的损失定义为异常。设备退化检测方法的评估现在包括计算测试集中所有数据点的重建损失,并将损失与将其标记为异常的定义阈值进行比较。
Model evaluation on test data:
利用上述方法,我们计算了轴承失效前一段时间内试验数据的重建损失,如下图所示。
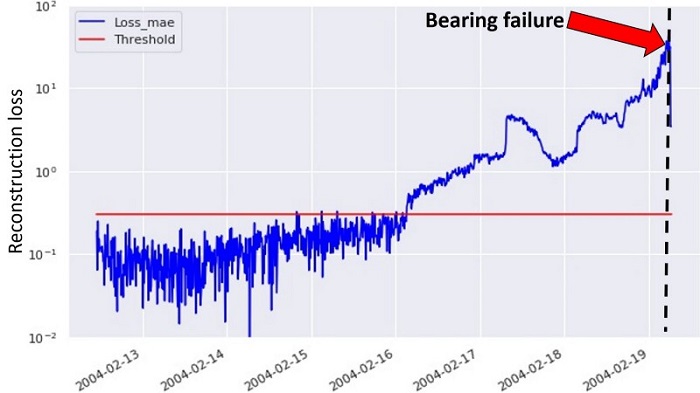
在上图中,蓝色点对应重建损失,而红色线代表标记异常的定义阈值。轴承故障发生在数据集的末尾,用黑色虚线表示。这也说明,这种建模方法能够在实际故障发生前3天(重建损失超过阈值)检测到即将发生的设备故障。
Results summary
从以上两个不同的异常检测方法部分可以看出,这两种方法都能在实际故障发生前几天成功检测到即将发生的设备故障。在实际场景中,这将允许在故障发生之前采取预测措施(维护/维修),这意味着既节省了成本,又对设备故障的HSE方面具有潜在的重要性。
随着通过传感器捕获数据的成本降低,以及设备之间的连接增加,能够从数据中提取有价值的信息变得越来越重要。在大量数据中发现模式是机器学习和统计的领域,在我看来,利用这些数据中隐藏的信息来提高几个不同领域的性能有着很大的潜力。正如本文所述,异常检测和状态监测只是众多可能性之一。