推荐系统主要试图预测user对item的评分或是偏好,通过评分的高低进行针对性的推荐。纵观各互联网大公司,几乎都会采用使用到推荐服务,比如:新闻推荐、广告推荐、商品推荐、书籍推荐等等。本文主要介绍如何使用keras训练embedding weights进而进行推荐。
前言
关于推荐系统,值得一提的是,推荐系统存在的“冷启动”问题,关于“冷启动”,主要分以下三类:
- 用户冷启动:即新来一个用户,如何做个性化推荐;
- 物品冷启动:即新的物品如何推荐给可能对它感兴趣的用户。
- 系统冷启动:即如何在一个新开发的网站(没有用户,没有用户行为,只有部分物品信息)上设计个性化推荐系统,从而在项目刚发布时就让用户体会到个性化推荐。
一个推荐系统可分为两个阶段:第一、召回阶段: 因为单个召回算法得到的结果一般都很难满足业务需求,所以通常都采取多路召回方式,如热门推荐、协同过滤、主题模型、内容召回以及模型召回等;第二、排序阶段:对多个召回方法的结果进行统一打分并排序,选出最优Top K。然而本文介绍的方法并不能解决冷启动问题,但是也算是一种召回策略。关于“冷启动”,后续再进行深入探讨。使用神经网络训练Embedding的几个步骤要点:
- 收集数据:神经网络需要大量的训练样本;
- 数据处理:根据具体问题将数据按照embedding的场景标准进行处理;
- 训练weights:建立embedding模型训练weights;
- 使用weights:使用Embedding weight进行recommendation和visualizations.
下面根据这几个步骤进行详细探讨,最终将给出一个推荐结果。
数据收集
假设我们获取的已知数据如下:
- doc的相关信息,包括:title、content(部分正文)
- user对doc的点击事件。
目的:给用户推荐Top N个没有阅读过的doc。
数据处理
Item2vec中把用户浏览的item集合等价于word2vec中的word的序列,即句子(忽略了商品序列空间信息spatial information) 。出现在同一个集合的商品对视为 positive
本文主要介绍如何给已有的用户进行推荐。用户点击过一篇doc,说明用户对doc产生了一定的兴趣,当我们把每个doc用实体词标签标记之后,就相当于用户对这些实体词感兴趣[user_id, keywords],其中keywords是用“|”分隔的词的集合。当我们将用户与多篇doc关联起来之后,就可以得到用户与实体词的兴趣。最后可以使用[user_id, keyword, score]进行标记。
user_keywords.csv文件内容如下,GitHub链接:user_keywords.csv:
1
2
3
4
5
6
7
8
9
| user_id keywords
113 新闻推荐|资讯推荐|内容推荐|文本分类|人工分类|自然语言处理|聚类|分类|冷启动
143 网络|睡眠|精神衰弱|声音|人工分类
123 新年愿望|梦想|2018|辞旧迎新
234 父母|肩头|饺子|蔬菜块|青春叛逆期|声音
117 新闻推荐|内容推荐|文本分类|人工分类|自然语言处理|聚类|分类|冷启动
119 新闻推荐|资讯推荐|人工分类|自然语言处理|聚类|分类|冷启动
12 新闻推荐|资讯推荐|内容推荐|文本分类|聚类|分类|冷启动
122 机器学习|新闻推荐|梦想|人工分类|自然语言处理
|
首先,我们通过pandas加载数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
"""
Created on Sat Jan 5 15:34:34 2019
@author: liudiwei
"""
import pandas as pd
import numpy as np
import random
from keras.layers import Input, Embedding, Dot, Reshape, Dense
from keras.models import Model
random.seed(100)
user_keywords = pd.read_csv("user_keywords.csv")
|
通过数据处理之后可以得到user_keywords, user_index, keyword_index:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def date_process(user_item):
""
1. user_item: user and item information, user_id, keywords, keyword_index
2. user_index: user to index
3. item_index:item to index
""
user_item["keywords"] = user_item["keywords"].apply(lambda x: x.split("|"))
keyword_list = []
for i in user_item["keywords"]:
keyword_list.extend(i)
#word count
item_count = pd.DataFrame(pd.Series(keyword_list).value_counts())
# add index to word_count
item_count['id'] = list(range(0, len(item_count)))
#将word的id对应起来
map_index = lambda x: list(item_count['id'][x])
user_item['keyword_index'] = user_item['keywords'].apply(map_index) #速度太慢
#create user_index, item_index
user_index = { v:k for k,v in user_item["user_id"].to_dict().items()}
item_index = item_count["id"].to_dict()
return user_item, user_index, item_index
user_keywords, user_index, keyword_index = date_process(user_keywords)
|
接下来,需要模拟一个分类或者回归的场景,用于学习embedding的weights。这里,我们模拟一个分类场景!
训练分类模型
注意,这里主要是模拟场景,并非做真的分类模型。训练模型的预测结果不是我们的最终目的,我们的目的是得到模型的parameters,即weights,所以,我们不需要真正的care模型结果是否精确。
对于Embedding的weights,主要有三个作用:
- 在embedding Space中找到某个样本点
top K的最近邻;
- 作为machine learning model的input
- Visualization:低维空间可视化
这里注重分析第1点和第3点。下面,先来构建正负样本。
模拟正负样本
通过数据构造,我们得到了user与keyword的关系,知道每个user对keyword的喜好程度。为了构建分类模型,这里我们将已有的user与keyword的对应关系作为正样本,负样本通过人工的从user集合与keyword集合进行构造,当出现的user与keyword对不在已有的数据内,我们就将其作为负样本。
1
2
3
4
5
6
7
8
9
10
11
12
| def create_pairs(user_keywords, user_index):
"""
generate user, keyword pair list
"""
pairs = []
def doc2tag(pairs, x):
for index in x["keyword_index"]:
pairs.append((user_index[x["user_id"]], index))
user_keywords.apply(lambda x: doc2tag(pairs, x), axis=1)
return pairs
pairs = create_pairs(user_keywords, user_index)
|
通过create_pairs方法,可以得到user与keyword的pairs。
Embedding模型
Embedding model的五个layer:
- Input: user与keyword同时作为输入;
- Embedding: 每个user和keyword使用同样的embedding size;
- Dot: 使用dot product合并embedding;
- Reshape: 将点积Reshape为一个值;
- Dense: 使用sigmoid激活函数处理output。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| def build_embedding_model(embedding_size = 50, classification = False):
"""训练embedding模型"""
user = Input(name = 'user', shape = [1])
keyword = Input(name = 'keyword', shape = [1])
user_embedding = Embedding(name = 'user_embedding',
input_dim = len(user_index),
output_dim = embedding_size)(user)
keyword_embedding = Embedding(name = 'keyword_embedding',
input_dim = len(keyword_index),
output_dim = embedding_size)(keyword)
merged = Dot(name = 'dot_product', normalize = True,
axes = 2)([user_embedding, keyword_embedding])
merged = Reshape(target_shape = [1])(merged)
out = Dense(1, activation = 'sigmoid')(merged)
model = Model(inputs = [user, keyword], outputs = out)
model.compile(optimizer = 'Adam', loss = 'binary_crossentropy',
metrics = ['accuracy'])
return model
model = build_embedding_model(embedding_size = 20, classification = False)
|
batch训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| def generate_batch(pairs, n_positive = 50, negative_ratio = 1.0):
batch_size = n_positive * (1 + negative_ratio)
batch = np.zeros((batch_size, 3))
while True:
for idx, (user_id, keyword_id) in enumerate(random.sample(pairs, n_positive)):
batch[idx, :] = (user_id, keyword_id, 1)
idx += 1
while idx < batch_size:
random_user = random.randrange(len(user_index))
random_keyword = random.randrange(len(keyword_index))
if (random_user, random_keyword) not in pairs:
batch[idx, :] = (random_user, random_keyword, 0)
idx += 1
np.random.shuffle(batch)
yield {'user': batch[:, 0], 'keyword': batch[:, 1]}, batch[:, 2]
n_positive = len(pairs)
gen = generate_batch(pairs, n_positive, negative_ratio = 1)
h = model.fit_generator(gen, epochs = 100, steps_per_epoch = len(pairs) // n_positive)
|
提取user weight
当模型训练完之后,我们可以通过下面的方法提取user的weight,提取方法如下:
1
2
3
|
user_layer = model.get_layer('user_embedding')
user_weights = user_layer.get_weights()[0]
|
user_weights是用户权重集合,每一行表示一个用户,相当于通过embedding训练user的向量表示,接下来可以进一步对用户进行可视化分析,同时可以通过计算相似度得到每个用户最相似的K个用户。
Visualization
对上面训练得到的weights,通过PCA可视化,我们可以看到几个user之间的空间关系,代码如下:
1
2
3
4
5
6
7
8
9
| from sklearn.decomposition import PCA
import seaborn as sns
def pca_show():
pca = PCA(n_components=2)
pca_result = pca.fit_transform(user_weights)
sns.jointplot(x=pca_result[:,0], y=pca_result[:,1])
pca_show()
|
可视化效果:
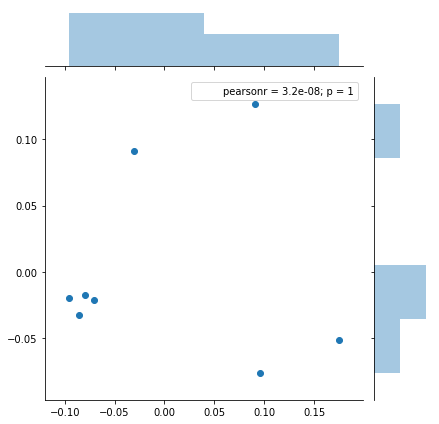
PCA结果:相同的几个样本点有一定的聚合性
我们可以看到,有着相同keyword喜好的user呈现出一定的聚合性。
Top K推荐
上面我们假设了每篇doc的keywords就是user对应的keywords,因此,我们可以直接通过计算weights 的cosine相似度进行推荐。
1
2
3
4
| #calculate cosine similarity
from sklearn.metrics.pairwise import cosine_similarity
cos = cosine_similarity(user_weights[5:6], user_weights)
recommendations = cos[0].argsort()[-4:][::-1]
|
结果为:[5、0、4、6],去掉第一个为自己本身,我们可以得到推荐下标为0、4、6的三篇用户。然后我们可以从这几个用户的user behavior里面,筛选出最近点击的或者最喜欢的doc给用户119。
下一步
上面的方法主要是找到user的向量表示,类似于user-cf,通过表示向量我们可以计算出用户最相似的其它用户,进而进行推荐。下一步的推荐策略还可以进一步扩展:
- 如何准确对用户推荐doc:可以采用user_similarity_score * user_doc_score,然后取top N;
- 训练基于doc的embedding,对每篇doc进行推荐;
完整的Demo代码:recommend.py
References
- neural network embeddings explained
- machine learning cosin similarity for vector space models
- Google Tensorflows Embedding Projector
- Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
- Item2vec: Neural Item Embedding for Collaborative Filtering
- Building a Recommendation System Using Neural Network Embeddings